Introduction
Hydroflow is a compiler for low-latency dataflow programs, written in Rust. Hydroflow is the runtime library for the Hydro language stack, which is under development as a complete compiler stack for distributed programming languages.
Hydroflow is designed with two goals in mind:
- Expert developers can program Hydroflow directly to build components in a distributed system.
- Higher levels of the Hydro stack will offer friendlier languages with more abstractions, and treat Hydroflow as a compiler target.
Hydroflow provides a DSL—a surface syntax—embedded in Rust, which compiles to high-efficiency machine code. As the lowest level of the Hydro stack, Hydroflow requires some knowledge of Rust to use.
This Book
This book will teach you how to set up your environment to get started with Hydroflow, and how to program in the Hydroflow surface syntax.
Keep in mind that Hydroflow is under active development and is constantly changing. However the code in this book is tested with the Hydroflow library so should always be up-to-date.
If you have any questions, feel free to create an issue on Github.
Quickstart
This section will get you up and running with Rust and Hydroflow, and work you through a set of concrete examples illustrating much of what you need to know to get productive with Hydroflow.
Setup
This section explains how to get Hydroflow running, either for development or usage, even if you are not familiar with Rust development.
Installing Rust
First you will need to install Rust. We recommend the conventional installation
method, rustup, which allows you to easily manage and update Rust versions.
The link in the previous line will take you to the Rust website that shows you how to
install rustup and the Rust package manager cargo (and the
internally-used rustc compiler). cargo is Rust's main development tool,
used for building, running, and testing Rust code.
The following cargo commands will come in handy:
cargo check --all-targets- Checks the workspace for any compile-time errors.cargo build --all-targets- Builds all projects/tests/benchmarks/examples in the workspace.cargo clean- Cleans the build cache, sometimes needed if the build is acting up.cargo test- Runs tests in the workspace.cargo run -p hydroflow --example <example name>- Run an example program inhydroflow/examples.
To learn Rust see the official Learn Rust page. Here are some good resources:
- The Rust Programming Language, AKA "The Book"
- Learn Rust With Entirely Too Many Linked Lists is a good way to learn Rust's ownership system and its implications.
In this book we will be using the Hydroflow template generator, which we recommend
as a starting point for your Hydroflow projects. For this purpose you
will need to install the cargo-generate tool:
cargo install cargo-generate
VS Code Setup
We recommend using VS Code with the rust-analyzer extension (and NOT the
Rust extension). To enable the pre-release version of rust-analyzer
(required by some new nightly syntax we use, at least until 2022-03-14), click
the "Switch to Pre-Release Version" button next to the uninstall button.
Setting up a Hydroflow Project
The easiest way to get started with Hydroflow is to begin with a template project. Create a directory where you'd like to put that project, direct your terminal there and run:
cargo generate hydro-project/hydroflow-template
You will be prompted to name your project. The cargo generate command will create a subdirectory
with the relevant files and folders.
As part of generating the project, the hydroflow library will be downloaded as a dependency.
You can then open the project in VS Code or IDE of your choice, or
you can simply build the template project with cargo build.
cd <project name>
cargo build
This should return successfully.
The template provides a simple working example of a Hydroflow program. As a sort of "hello, world" of distributed systems, it implements an "echo server" that simply echoes back the messages you sent it; it also implements a client to test the server. We will replace the code in that example with our own, but it's a good idea to run it first to make sure everything is working.
We call a running Hydroflow binary a transducer.
Start by running a transducer for the server:
% cargo run -- --role server
Listening on 127.0.0.1:<port>
Server live!
Take note of the server's port number, and in a separate terminal, start a client transducer:
% cd <project name>
% cargo run -- --role client --server-addr 127.0.0.1:<port>
Listening on 127.0.0.1:<client_port>
Connecting to server at 127.0.0.1:<port>
Client live!
Now you can type strings in the client, which are sent to the server, echo'ed back, and printed at the client. E.g.:
Hello!
2022-12-20 18:51:50.181647 UTC: Got Echo { payload: "Hello!", ts: 2022-12-20T18:51:50.180874Z } from 127.0.0.1:61065
Alternative: Checking out the Hydroflow Repository
This book will assume you are using the template project, but some Rust experts may want to get started with Hydroflow by cloning and working in the repository directly. You should fork the repository if you want to push your changes.
To clone the repo, run:
git clone git@github.com:hydro-project/hydroflow.git
Hydroflow requires nightly Rust, but the repo is already configured for it via
rust-toolchain.toml.
You can then open the repo in VS Code or IDE of your choice. In VS Code, rust-analyzer
will provide inline type and error messages, code completion, etc.
To work with the repository, it's best to start with an "example", found in the
hydroflow/examples folder.
These examples are included via the hydroflow/Cargo.toml file,
so make sure to add your example there if you create a new one. The simplest
example is the echo server.
The Hydroflow repository is set up as a workspace,
i.e. a repo containing a bunch of separate packages, hydroflow is just the
main one. So if you want to work in a proper separate cargo package, you can
create one and add it into the root Cargo.toml,
much like the provided template.
Simplest Example
In this example we will cover:
- Modifying the Hydroflow template project
- How Hydroflow program specs are embedded inside Rust
- How to execute a simple Hydroflow program
- Two Hydroflow operators:
source_iterandfor_each
Lets start out with the simplest possible Hydroflow program, which prints out
the numbers in 0..10.
Create a clean template project:
% cargo generate hydro-project/hydroflow-template
⚠️ Favorite `hydro-project/hydroflow-template` not found in config, using it as a git repository: https://github.com/hydro-project/hydroflow-template.git
🤷 Project Name: simple
🔧 Destination: /Users/jmh/code/sussudio/simple ...
🔧 project-name: simple ...
🔧 Generating template ...
[ 1/11] Done: .gitignore [ 2/11] Done: Cargo.lock [ 3/11] Done: Cargo.toml [ 4/11] Done: README.md [ 5/11] Done: rust-toolchain.toml [ 6/11] Done: src/client.rs [ 7/11] Done: src/helpers.rs [ 8/11] Done: src/main.rs [ 9/11] Done: src/protocol.rs [10/11] Done: src/server.rs [11/11] Done: src 🔧 Moving generated files into: `<dir>/simple`...
💡 Initializing a fresh Git repository
✨ Done! New project created <dir>/simple
Change directory into the resulting simple folder or open it in your IDE. Then edit the src/main.rs file, replacing
all of its contents with the following code:
use hydroflow::hydroflow_syntax; pub fn main() { let mut flow = hydroflow_syntax! { source_iter(0..10) -> for_each(|n| println!("Hello {}", n)); }; flow.run_available(); }
And then run the program:
% cargo run
Hello 0
Hello 1
Hello 2
Hello 3
Hello 4
Hello 5
Hello 6
Hello 7
Hello 8
Hello 9
Understanding the Code
Although this is a trivial program, it's useful to go through it line by line.
use hydroflow::hydroflow_syntax;This import gives you everything you need from Hydroflow to write code with Hydroflow's surface syntax.
Next, inside the main method we specify a flow by calling the
hydroflow_syntax! macro. We assign the resulting Hydroflow instance to
a mutable variable flow––mutable because we will be changing its status when we run it.
use hydroflow::hydroflow_syntax;
pub fn main() {
let mut flow = hydroflow_syntax! {
source_iter(0..10) -> for_each(|n| println!("Hello {}", n));
};Hydroflow surface syntax defines a "flow" consisting of operators connected via -> arrows.
This simplest example uses a simple two-step linear flow.
It starts with a source_iter operator that takes the Rust
iterator 0..10 and iterates it to emit the
numbers 0 through 9. That operator then passes those numbers along the -> arrow downstream to a
for_each operator that invokes its closure argument to print each
item passed in.
The Hydroflow surface syntax is merely a specification; it does not actually do anything
until we run it.
We run the flow from within Rust via the run_available() method.
flow.run_available();Note that run_available() runs the Hydroflow graph until no more work is immediately
available. In this example flow, running the graph drains the iterator completely, so no
more work will ever be available. In future examples we will use external inputs such as
network ingress, in which case more work might appear at any time.
A Note on Project Structure
The template project is intended to be a starting point for your own Hydroflow project, and you can add files and directories as you see fit. The only requirement is that the src/main.rs file exists and contains a main() function.
In this simplest example we did not use a number of the files in the template: notably everything in the src/ subdirectory other than src/main.rs. If you'd like to delete those extraneous files you can do so, but it's not necessary, and we'll use them in subsequent examples.
Simple Example
In this example we will cover some additional standard Hydroflow operators:
Lets build on the simplest example to explore some of the operators available
in Hydroflow. You may be familiar with operators such as map(...),
filter(...), flatten(...),
etc. from Rust iterators or from other programming languages, and these are
also available in Hydroflow.
In your simple project, replace the contents of src/main.rs with the following:
use hydroflow::hydroflow_syntax; pub fn main() { let mut flow = hydroflow_syntax! { source_iter(0..10) -> map(|n| n * n) -> filter(|&n| n > 10) -> map(|n| (n..=n+1)) -> flatten() -> for_each(|n| println!("Howdy {}", n)); }; flow.run_available(); }
Let's take this one operator at a time, starting after the source_iter operator we saw in the previous example.
-
-> map(|n| n * n)transforms each element individually as it flows through the subgraph. In this case, we square each number. -
Next,
-> filter(|&n| n > 10)only passes along squared numbers that are greater than 10. -
The subsequent
-> map(|n| (n..=n+1))uses standard Rust syntax to convert each numberninto aRangeInclusive[n,n+1]. -
The
-> flatten()operator converts the ranges back into a stream of the individual numbers which they contain. -
Finally we use the now-familiar
for_eachoperator to print each number.
Now let's run the program:
% cargo run
<build output>
Howdy 16
Howdy 17
Howdy 25
Howdy 26
Howdy 36
Howdy 37
Howdy 49
Howdy 50
Howdy 64
Howdy 65
Howdy 81
Howdy 82
Rewriting with Composite Operators
We can also express the same program with more aggressive use of composite operators like
filter_map() and flat_map(). Hydroflow will compile these down to the same
machine code.
Replace the contents of src/main.rs with the following:
use hydroflow::hydroflow_syntax; pub fn main() { let mut flow = hydroflow_syntax! { source_iter(0..10) -> filter_map(|n| { let n2 = n * n; if n2 > 10 { Some(n2) } else { None } }) -> flat_map(|n| (n..=n+1)) -> for_each(|n| println!("G'day {}", n)); }; flow.run_available(); }
Results:
% cargo run
<build output>
G'day 16
G'day 17
G'day 25
G'day 26
G'day 36
G'day 37
G'day 49
G'day 50
G'day 64
G'day 65
G'day 81
G'day 82
An Example With Streaming Input
In this example we will cover:
- the input
channelconcept, which streams data in from outside the Hydroflow spec- the
source_streamoperator that brings channel input into Hydroflow- Rust syntax to programmatically send data to a (local) channel
In our previous examples, data came from within the Hydroflow spec, via Rust iterators and the source_iter operator. In most cases, however, data comes from outside the Hydroflow spec. In this example, we'll see a simple version of this idea, with data being generated on the same machine and sent into the channel programmatically via Rust.
For discussion, we start with a skeleton much like before:
use hydroflow::hydroflow_syntax; pub fn main() { let mut hydroflow = hydroflow_syntax! { // code will go here }; hydroflow.run_available(); }
TODO: Make the following less intimidating to users who are not Tokio experts.
To add a new external input
channel, we can use the hydroflow::util::unbounded_channel() function in Rust before we declare the Hydroflow spec:
let (input_example, example_recv) = hydroflow::util::unbounded_channel::<usize>();Under the covers, this is a multiple-producer/single-consumer (mpsc) channel provided by Rust's tokio library, which is usually the appropriate choice for an inbound Hydroflow stream.
Think of it as a high-performance "mailbox" that any sender can fill with well-typed data.
The Rust ::<usize> syntax uses what is affectionately
called the "turbofish", which is how type parameters (generic arguments) are
supplied to generic types and functions. In this case it specifies that this tokio channel
transmits items of type usize.
The returned example_recv value can be used via a source_stream
to build a Hydroflow subgraph just like before.
Here is the same program as before, but using the
input channel. Back in the simple project, replace the contents of src/main.rs with the following:
use hydroflow::hydroflow_syntax; pub fn main() { // Create our channel input let (input_example, example_recv) = hydroflow::util::unbounded_channel::<usize>(); let mut flow = hydroflow_syntax! { source_stream(example_recv) -> filter_map(|n: usize| { let n2 = n * n; if n2 > 10 { Some(n2) } else { None } }) -> flat_map(|n| (n..=n+1)) -> for_each(|n| println!("Ahoy, {}", n)); }; println!("A"); input_example.send(1).unwrap(); input_example.send(0).unwrap(); input_example.send(2).unwrap(); input_example.send(3).unwrap(); input_example.send(4).unwrap(); input_example.send(5).unwrap(); flow.run_available(); println!("B"); input_example.send(6).unwrap(); input_example.send(7).unwrap(); input_example.send(8).unwrap(); input_example.send(9).unwrap(); flow.run_available(); }
% cargo run
<build output>
A
Ahoy, 16
Ahoy, 17
Ahoy, 25
Ahoy, 26
B
Ahoy, 36
Ahoy, 37
Ahoy, 49
Ahoy, 50
Ahoy, 64
Ahoy, 65
Ahoy, 81
Ahoy, 82
At the bottom of main.rs we can see how to programatically supply usize-typed inputs with the tokio
.send() method. We call Rust's .unwrap() method to ignore the error messages from
.send() in this simple case. In later examples we'll see how to
allow for data coming in over a network.
Graph Neighbors
In this example we cover:
- Assigning sub-flows to variables
- Our first multi-input operator,
join- Indexing multi-input operators by prepending a bracket expression
- The
uniqueoperator for removing duplicates from a stream- Visualizing hydroflow code via
flow.meta_graph().to_mermaid()- A first exposure to the concepts of strata and ticks
So far all the operators we've used have one input and one output and therefore create a linear flow of operators. Let's now take a look at a Hydroflow program containing an operator which has multiple inputs; in the following examples we'll extend this to multiple outputs.
To motivate this, we are going to start out on a little project of building a flow-based algorithm
for the problem of graph reachability.
Given an abstract graph—represented as data in the form of a streaming list of edges—which
vertices can be reached from a vertex passed in as the origin? It turns out this is fairly
naturally represented as a dataflow program.
Note on terminology: In each of the next few examples, we're going to write a Hydroflow program (a dataflow graph) to process data that itself represents some other graph! To avoid confusion, in these examples, we'll refer to the Hydroflow program as a "flow" or "program", and the data as a "graph" of "edges" and "vertices".
But First: Graph Neighbors
Graph reachability exercises a bunch of concepts at once, so we'll start here with a simpler flow that finds graph neighbors: vertices that are just one hop away.
Our graph neighbors Hydroflow program will take
our initial origin vertex as one input, and join it another input that streams in all the edges—this
join will stream out the vertices that are one hop (edge) away from the starting vertex.
Here is an intuitive diagram of that dataflow program (we'll see complete, autogenerated Hydroflow diagrams below):
graph TD
subgraph sources
01[Stream of Edges]
end
subgraph neighbors of origin
00[Origin Vertex]
20("V ⨝ E")
40[Output]
00 --> 20
01 ---> 20
20 --> 40
end
Lets take a look at some Hydroflow code that implements the program. In your simple project,
replace the contents of src/main.rs with the following:
use hydroflow::hydroflow_syntax; pub fn main() { // An edge in the input data = a pair of `usize` vertex IDs. let (edges_send, edges_recv) = hydroflow::util::unbounded_channel::<(usize, usize)>(); let mut flow = hydroflow_syntax! { // inputs: the origin vertex (vertex 0) and stream of input edges origin = source_iter(vec![0]); stream_of_edges = source_stream(edges_recv); // the join my_join = join() -> flat_map(|(src, (_, dst))| [src, dst]); origin -> map(|v| (v, ())) -> [0]my_join; stream_of_edges -> [1]my_join; // the output my_join -> unique() -> for_each(|n| println!("Reached: {}", n)); }; println!( "{}", flow.meta_graph() .expect("No graph found, maybe failed to parse.") .to_mermaid() ); edges_send.send((0, 1)).unwrap(); edges_send.send((2, 4)).unwrap(); edges_send.send((3, 4)).unwrap(); edges_send.send((1, 2)).unwrap(); edges_send.send((0, 3)).unwrap(); edges_send.send((0, 3)).unwrap(); flow.run_available(); }
Run the program and focus on the last three lines of output, which come from flow.run_available():
% cargo run
<build output>
<graph output>
Reached: 0
Reached: 3
Reached: 1
That looks right: the edges we "sent" into the flow that start at 0 are
(0, 1) and (0, 3), so the nodes reachable from 0 in 0 or 1 hops are 0, 1, 3.
Note: When you run the program you may see the lines printed out in a different order. That's OK; the flow we're defining here is producing a
setof nodes, so the order in which they are printed out is not specified. Thesort_byoperator can be used to sort the output of a flow.
Examining the Hydroflow Code
In the code, we want to start out with the origin vertex, 0,
and the stream of edges coming in. Because this flow is a bit more complex
than our earlier examples, we break it down into named "subflows", assigning them variable
names that we can reuse. Here we specify two subflows, origin and stream_of_edges:
origin = source_iter(vec![0]);
stream_of_edges = source_stream(edges_recv);The Rust syntax vec![0] constructs a vector with a single element, 0, which we iterate
over using source_iter.
We then set up a join() that we
name my_join, which acts like a SQL inner join.
// the join
my_join = join() -> flat_map(|(src, (_, dst))| [src, dst]);
origin -> map(|v| (v, ())) -> [0]my_join;
stream_of_edges -> [1]my_join;First, note the syntax for passing data into a subflow with multiple inputs requires us to prepend
an input index (starting at 0) in square brackets to the multi-input variable name or operator. In this example we have -> [0]my_join
and -> [1]my_join.
Hydroflow's join() API requires
a little massaging of its inputs to work properly.
The inputs must be of the form of a pair of elements (K, V1)
and (K, V2), and the operator joins them on equal keys K and produces an
output of (K, (V1, V2)) elements. In this case we only want to join on the key v and
don't have any corresponding value, so we feed origin through a map()
to generate (v, ()) elements as the first join input.
The stream_of_edges are (src, dst) pairs,
so the join's output is (src, ((), dst)) where dst are new neighbor
vertices. So the my_join variable feeds the output of the join through a flat_map to extract the pairs into 2-item arrays, which are flattened to give us a list of all vertices reached.
Finally we print the neighbor vertices as follows:
my_join -> unique() -> for_each(|n| println!("Reached: {}", n));The unique operator removes duplicates from the stream to make things more readable. Note that unique does not run in a streaming fashion, which we will talk about more below.
There's
also some extra code here, flow.meta_graph().expect(...).to_mermaid(), which tells
Hydroflow to
generate a diagram rendered by Mermaid showing
the structure of the graph, and print it to stdout. You can copy that text and paste it into the Mermaid Live Editor to see the graph, which should look as follows:
%%{init: {'theme': 'base', 'themeVariables': {'clusterBkg':'#ddd'}}}%%
flowchart TD
classDef pullClass fill:#02f,color:#fff,stroke:#000
classDef pushClass fill:#ff0,stroke:#000
linkStyle default stroke:#aaa,stroke-width:4px,color:red,font-size:1.5em;
subgraph "sg_1v1 stratum 0"
1v1[\"(1v1) <tt>source_iter(vec! [0])</tt>"/]:::pullClass
2v1[\"(2v1) <tt>source_stream(edges_recv)</tt>"/]:::pullClass
5v1[\"(5v1) <tt>map(| v | (v, ()))</tt>"/]:::pullClass
3v1[\"(3v1) <tt>join()</tt>"/]:::pullClass
4v1[\"(4v1) <tt>flat_map(| (src, (_, dst)) | [src, dst])</tt>"/]:::pullClass
1v1--->5v1
2v1--1--->3v1
5v1--0--->3v1
3v1--->4v1
end
subgraph "sg_2v1 stratum 1"
6v1[/"(6v1) <tt>unique()</tt>"\]:::pushClass
7v1[/"(7v1) <tt>for_each(| n | println! ("Reached: {}", n))</tt>"\]:::pushClass
6v1--->7v1
end
4v1--->8v1
8v1["(8v1) <tt>handoff</tt>"]:::otherClass
8v1===o6v1
Notice in the mermaid graph how Hydroflow separates the unique operator and its downstream dependencies into their own
stratum (plural: strata). Note also the edge coming into unique is bold and ends in a ball: this is because the input to unique is
``blocking'', meaning that unique should not run until all of the input on that edge has been received.
The stratum boundary before unique ensures that the blocking property is respected.
You may also be wondering why the nodes in the graph have different colors (and shapes, for readers who cannot distinguish
colors easily). The answer has nothing to do with the meaning of the program, only with the way that Hydroflow compiles
operators into Rust. Simply put, blue (wide-topped) boxes pull data, yellow (wide-bottomed) boxes push data, and the handoff is a special operator that buffers pushed data for subsequent pulling. Hydroflow always places a handoff
between a push producer and a pull consumer, for reasons explained in the Architecture chapter.
Strata and Ticks
Hydroflow runs each stratum in order, one at a time, ensuring all values are computed before moving on to the next stratum. Between strata we see a handoff, which logically buffers the output of the first stratum, and delineates the separation of execution between the 2 strata.
After all strata are run, Hydroflow returns to the first stratum; this begins the next tick. This doesn't really matter for this example, but it is important for long-running Hydroflow services that accept input from the outside world. More on this topic in the chapter on time.
Returning to the code, if you read the edges_send calls carefully, you'll see that the example data
has vertices (2, 4) that are more than one hop away from 0, which were
not output by our simple program. To extend this example to graph reachability,
we need to recurse: find neighbors of our neighbors, neighbors of our neighbors' neighbors, and so on. In Hydroflow,
this is done by adding a loop to the flow, as we'll see in our next example.
Graph Reachability
In this example we cover:
- Implementing a recursive algorithm (graph reachability) via cyclic dataflow
- Operators to merge data from multiple inputs (
merge), and send data to multiple outputs (tee)- Indexing multi-output operators by appending a bracket expression
- An example of how a cyclic dataflow in one stratum executes to completion before starting the next stratum.
To expand from graph neighbors to graph reachability, we want to find vertices that are connected not just to origin,
but also to vertices reachable transitively from origin. Said differently, a vertex is reachable from origin if it is
one of two cases:
- a neighbor of
originor - a neighbor of some other vertex that is itself reachable from
origin.
It turns out this is a very small change to our Hydroflow program! Essentially we want to take all the reached vertices we found in our graph neighbors program,
and treat them recursively just as we treated origin.
To do this in a language like Hydroflow, we introduce a cycle in the flow:
we take the join output and have it
flow back into the join input. The modified intuitive graph looks like this:
graph TD
subgraph sources
01[Stream of Edges]
end
subgraph reachable from origin
00[Origin Vertex]
10[Reached Vertices]
20("V ⨝ E")
40[Output]
00 --> 10
10 --> 20
20 --> 10
01 --> 20
20 --> 40
end
Note that we added a Reached Vertices box to the diagram to merge the two inbound edges corresponding to our
two cases above. Similarly note that the join box V ⨝ E now has two outbound edges; the sketch omits the operator
to copy ("tee") the output along
two paths.
Now lets look at a modified version of our graph neighbor code that implements this full program, including the loop as well as the Hydroflow merge and tee.
Modify src/main.rs to look like this:
use hydroflow::hydroflow_syntax; pub fn main() { // An edge in the input data = a pair of `usize` vertex IDs. let (edges_send, edges_recv) = hydroflow::util::unbounded_channel::<(usize, usize)>(); let mut flow = hydroflow_syntax! { // inputs: the origin vertex (vertex 0) and stream of input edges origin = source_iter(vec![0]); stream_of_edges = source_stream(edges_recv); reached_vertices = merge(); origin -> [0]reached_vertices; // the join my_join_tee = join() -> flat_map(|(src, ((), dst))| [src, dst]) -> tee(); reached_vertices -> map(|v| (v, ())) -> [0]my_join_tee; stream_of_edges -> [1]my_join_tee; // the loop and the output my_join_tee[0] -> [1]reached_vertices; my_join_tee[1] -> unique() -> for_each(|x| println!("Reached: {}", x)); }; println!( "{}", flow.meta_graph() .expect("No graph found, maybe failed to parse.") .to_mermaid() ); edges_send.send((0, 1)).unwrap(); edges_send.send((2, 4)).unwrap(); edges_send.send((3, 4)).unwrap(); edges_send.send((1, 2)).unwrap(); edges_send.send((0, 3)).unwrap(); edges_send.send((0, 3)).unwrap(); flow.run_available(); }
And now we get the full set of vertices reachable from 0:
% cargo run
<build output>
<graph output>
Reached: 3
Reached: 0
Reached: 2
Reached: 4
Reached: 1
Examining the Hydroflow Code
Let's review the significant changes here. First, in setting up the inputs we have the
addition of the reached_vertices variable, which uses the merge()
op to merge the output of two operators into one.
We route the origin vertex into it as one input right away:
reached_vertices = merge();
origin -> [0]reached_vertices;Note the square-bracket syntax for differentiating the multiple inputs to merge()
is the same as that of join() (except that merge can have an unbounded number of inputs,
whereas join() is defined to only have two.)
Now, join() is defined to only have one output. In our program, we want to copy
the joined output
output to two places: to the original for_each from above to print output, and also
back to the merge operator we called reached_vertices.
We feed the join() output
through a flat_map() as before, and then we feed the result into a tee() operator,
which is the mirror image of merge(): instead of merging many inputs to one output,
it copies one input to many different outputs. Each input element is cloned, in Rust terms, and
given to each of the outputs. The syntax for the outputs of tee() mirrors that of merge: we append
an output index in square brackets to the tee or variable. In this example we have
my_join_tee[0] -> and my_join_tee[1] ->.
Finally, we process the output of the join as passed through the tee.
One branch pushes reached vertices back up into the reached_vertices variable (which begins with a merge), while the other
prints out all the reached vertices as in the simple program.
my_join_tee[0] -> [1]reached_vertices;
my_join_tee[1] -> for_each(|x| println!("Reached: {}", x));Note the syntax for differentiating the outputs of a tee() is symmetric to that of merge(),
showing up to the right of the variable rather than the left.
Below is the diagram rendered by mermaid showing the structure of the full flow:
%%{init: {'theme': 'base', 'themeVariables': {'clusterBkg':'#ddd'}}}%%
flowchart TD
classDef pullClass fill:#02f,color:#fff,stroke:#000
classDef pushClass fill:#ff0,stroke:#000
linkStyle default stroke:#aaa,stroke-width:4px,color:red,font-size:1.5em;
subgraph "sg_1v1 stratum 0"
1v1[\"(1v1) <tt>source_iter(vec! [0])</tt>"/]:::pullClass
2v1[\"(2v1) <tt>source_stream(edges_recv)</tt>"/]:::pullClass
3v1[\"(3v1) <tt>merge()</tt>"/]:::pullClass
7v1[\"(7v1) <tt>map(| v | (v, ()))</tt>"/]:::pullClass
4v1[\"(4v1) <tt>join()</tt>"/]:::pullClass
5v1[/"(5v1) <tt>flat_map(| (src, ((), dst)) | [src, dst])</tt>"\]:::pushClass
6v1[/"(6v1) <tt>tee()</tt>"\]:::pushClass
10v1["(10v1) <tt>handoff</tt>"]:::otherClass
10v1--1--->3v1
1v1--0--->3v1
2v1--1--->4v1
3v1--->7v1
7v1--0--->4v1
4v1--->5v1
5v1--->6v1
6v1--0--->10v1
end
subgraph "sg_2v1 stratum 1"
8v1[/"(8v1) <tt>unique()</tt>"\]:::pushClass
9v1[/"(9v1) <tt>for_each(| x | println! ("Reached: {}", x))</tt>"\]:::pushClass
8v1--->9v1
end
6v1--1--->11v1
11v1["(11v1) <tt>handoff</tt>"]:::otherClass
11v1===o8v1
This is similar to the flow for graph neighbors, but has a few more operators that make it look
more complex. In particular, it includes the merge and tee operators, and a cycle-forming back-edge
that passes through an auto-generated handoff operator. This handoff is not a stratum boundary (after all, it connects stratum 0 to itself!) It simply enforces the rule that a push producer and a pull consumer must be separated by a handoff.
Meanwhile, note that there is once again a stratum boundary between the stratum 0 with its recursive loop, and stratum 1 that computes unique, with the blocking input. This means that Hydroflow will first run the loop of stratum 0 repeatedly until all the transitive reached vertices are found, before moving on to compute the unique reached vertices.
Graph Un-Reachability
In this example we cover:
- Extending a program with additional downstream logic.
- Hydroflow's (
difference) operator- Further examples of automatic stratification.
Our next example builds on the previous by finding vertices that are not reachable. To do this, we need to capture the set all_vertices, and use a difference operator to form the difference between that set of vertices and reachable_vertices.
Essentially we want a flow like this:
graph TD
subgraph sources
01[Stream of Edges]
end
subgraph reachable from origin
00[Origin Vertex]
10[Reached Vertices]
20("V ⨝ E")
00 --> 10
10 --> 20
20 --> 10
01 --> 20
end
subgraph unreachable
15[All Vertices]
30(All - Reached)
01 ---> 15
15 --> 30
10 --> 30
30 --> 40
end
40[Output]
This is a simple augmentation of our previous example. Replace the contents of src/main.rs with the following:
use hydroflow::hydroflow_syntax; pub fn main() { // An edge in the input data = a pair of `usize` vertex IDs. let (pairs_send, pairs_recv) = hydroflow::util::unbounded_channel::<(usize, usize)>(); let mut flow = hydroflow_syntax! { origin = source_iter(vec![0]); stream_of_edges = source_stream(pairs_recv) -> tee(); reached_vertices = merge()->tee(); origin -> [0]reached_vertices; // the join for reachable vertices my_join = join() -> flat_map(|(src, ((), dst))| [src, dst]); reached_vertices[0] -> map(|v| (v, ())) -> [0]my_join; stream_of_edges[1] -> [1]my_join; // the loop my_join -> [1]reached_vertices; // the difference all_vertices - reached_vertices all_vertices = stream_of_edges[0] -> flat_map(|(src, dst)| [src, dst]) -> tee(); unreached_vertices = difference(); all_vertices[0] -> [pos]unreached_vertices; reached_vertices[1] -> [neg]unreached_vertices; // the output all_vertices[1] -> unique() -> for_each(|v| println!("Received vertex: {}", v)); unreached_vertices -> for_each(|v| println!("unreached_vertices vertex: {}", v)); }; println!( "{}", flow.meta_graph() .expect("No graph found, maybe failed to parse.") .to_mermaid() ); pairs_send.send((5, 10)).unwrap(); pairs_send.send((0, 3)).unwrap(); pairs_send.send((3, 6)).unwrap(); pairs_send.send((6, 5)).unwrap(); pairs_send.send((11, 12)).unwrap(); flow.run_available(); }
Notice that we are now sending in some new pairs to test this code. The output should be:
% cargo run
<build output>
<graph output>
Received vertex: 12
Received vertex: 6
Received vertex: 11
Received vertex: 0
Received vertex: 5
Received vertex: 10
Received vertex: 3
unreached_vertices vertex: 12
unreached_vertices vertex: 11
Let's review the changes, all of which come at the end of the program. First,
we remove code to print reached_vertices. Then we define all_vertices to be
the vertices that appear in any edge (using familiar flat_map code from the previous
examples.) In the last few lines, we wire up a
difference operator
to compute the difference between all_vertices and reached_vertices; note
how we wire up the pos and neg inputs to the difference operator!
Finally we print both all_vertices and unreached_vertices.
The auto-generated mermaid looks like so:
%%{init: {'theme': 'base', 'themeVariables': {'clusterBkg':'#ddd'}}}%%
flowchart TD
classDef pullClass fill:#02f,color:#fff,stroke:#000
classDef pushClass fill:#ff0,stroke:#000
linkStyle default stroke:#aaa,stroke-width:4px,color:red,font-size:1.5em;
subgraph "sg_1v1 stratum 0"
1v1[\"(1v1) <tt>source_iter(vec! [0])</tt>"/]:::pullClass
8v1[\"(8v1) <tt>map(| v | (v, ()))</tt>"/]:::pullClass
6v1[\"(6v1) <tt>join()</tt>"/]:::pullClass
7v1[\"(7v1) <tt>flat_map(| (src, ((), dst)) | [src, dst])</tt>"/]:::pullClass
4v1[\"(4v1) <tt>merge()</tt>"/]:::pullClass
5v1[/"(5v1) <tt>tee()</tt>"\]:::pushClass
15v1["(15v1) <tt>handoff</tt>"]:::otherClass
15v1--->8v1
1v1--0--->4v1
8v1--0--->6v1
6v1--->7v1
7v1--1--->4v1
4v1--->5v1
5v1--0--->15v1
end
subgraph "sg_2v1 stratum 0"
2v1[\"(2v1) <tt>source_stream(pairs_recv)</tt>"/]:::pullClass
3v1[/"(3v1) <tt>tee()</tt>"\]:::pushClass
9v1[/"(9v1) <tt>flat_map(| (src, dst) | [src, dst])</tt>"\]:::pushClass
10v1[/"(10v1) <tt>tee()</tt>"\]:::pushClass
2v1--->3v1
3v1--0--->9v1
9v1--->10v1
end
subgraph "sg_3v1 stratum 1"
12v1[/"(12v1) <tt>unique()</tt>"\]:::pushClass
13v1[/"(13v1) <tt>for_each(| v | println! ("Received vertex: {}", v))</tt>"\]:::pushClass
12v1--->13v1
end
subgraph "sg_4v1 stratum 1"
11v1[\"(11v1) <tt>difference()</tt>"/]:::pullClass
14v1[/"(14v1) <tt>for_each(| v | println! ("unreached_vertices vertex: {}", v))</tt>"\]:::pushClass
11v1--->14v1
end
3v1--1--->16v1
5v1--1--->18v1
10v1--0--->17v1
10v1--1--->19v1
16v1["(16v1) <tt>handoff</tt>"]:::otherClass
16v1--1--->6v1
17v1["(17v1) <tt>handoff</tt>"]:::otherClass
17v1--pos--->11v1
18v1["(18v1) <tt>handoff</tt>"]:::otherClass
18v1==neg===o11v1
19v1["(19v1) <tt>handoff</tt>"]:::otherClass
19v1===o12v1
If you look carefully, you'll see two subgraphs labeled with stratum 0, and two with
stratum 1. The reason the strata were broken into subgraphs has nothing to do with
correctness, but rather the way that Hydroflow graphs are compiled and scheduled, as
discussed in the chapter on Architecture.
All the subgraphs labeled stratum 0 are run first to completion,
and then all the subgraphs labeled stratum 1 are run. This captures the requirements of the unique and difference operators used in the lower subgraphs: each has to wait for its full inputs before it can start producing output. Note
how the difference operator has two inputs (labeled pos and neg), and only the neg input shows up as blocking (with the bold edge ending in a ball).
Networked Services 1: EchoServer
In this example we cover:
- The standard project template for networked Hydroflow services.
- Rust's
clapcrate for command-line options- Defining message types
- Destination operators (e.g. for sending data to a network)
- Network sources and dests with built-in serde (
source_stream_serde,dest_sink_serde)- The
source_stdinsource- Long-running services via
run_async
Our examples up to now have been simple single-node programs, to get us comfortable with Hydroflow's surface syntax. But the whole point of Hydroflow is to help us write distributed programs or services that run on a cluster of machines!
In this example we'll study the "hello, world" of distributed systems -- a simple echo server. It will listen on a UDP port, and send back a copy of any message it receives, with a timestamp. We will also look at a client to accept strings from the command line, send them to the echo server, and print responses.
We will use a fresh hydroflow-template project template to get started. Change to the directory where you'd like to put your project, and once again run:
cargo generate hydro-project/hydroflow-template
Then change directory into the resulting project.
The README.md for the template project is a good place to start. It contains a brief overview of the project structure, and how to build and run the example. Here we'll spend more time learning from the code.
Hydroflow Project Structure
The Hydroflow template project auto-generates this example for us. If you prefer, you can find the source in the examples/echo_server directory of the Hydroflow repository.
The directory structure encouraged by the template is as follows:
project/README.md # documentation
project/Cargo.toml # package and dependency info
project/src/main.rs # main function
project/src/protocol.rs # message types exchanged between roles
project/src/helpers.rs # helper functions used by all roles
project/src/<roleA>.rs # service definition for role A (e.g. server)
project/src/<roleB>.rs # service definition for role B (e.g. client)
In the default example, the roles we use are Client and Server, but you can imagine different roles depending on the structure of your service or application.
main.rs
We start with a main function that parses command-line options, and invokes the appropriate
role-specific service.
After a prelude of imports, we start by defining a Rust enum for the Roles that the service supports.
use clap::{Parser, ValueEnum};
use client::run_client;
use hydroflow::tokio;
use hydroflow::util::{bind_udp_bytes, ipv4_resolve};
use server::run_server;
use std::net::SocketAddr;
mod client;
mod helpers;
mod protocol;
mod server;
#[derive(Clone, ValueEnum, Debug)]
enum Role {
Client,
Server,
}Following that, we use Rust's clap (Command Line Argument Parser) crate to parse command-line options:
#[derive(Parser, Debug)]
struct Opts {
#[clap(value_enum, long)]
role: Role,
#[clap(long, value_parser = ipv4_resolve)]
addr: Option<SocketAddr>,
#[clap(long, value_parser = ipv4_resolve)]
server_addr: Option<SocketAddr>,
}This sets up 3 command-line flags: role, addr, and server_addr. Note how the addr and server_addr flags are made optional via wrapping in a Rust Option; by contrast, the role option is required. The clap crate will parse the command-line options and populate the Opts struct with the values. clap handles parsing the command line strings into the associated Rust types -- the value_parser attribute tells clap to use Hydroflow's ipv4_resolve helper function to parse a string like "127.0.0.1:6552" into a SocketAddr.
This brings us to the main function itself. It is prefaced by a #[tokio::main] attribute, which is a macro that sets up the tokio runtime. This is necessary because Hydroflow uses the tokio runtime for asynchronous execution as a service.
#[tokio::main]
async fn main() {
// parse command line arguments
let opts = Opts::parse();
// if no addr was provided, we ask the OS to assign a local port by passing in "localhost:0"
let addr = opts
.addr
.unwrap_or_else(|| ipv4_resolve("localhost:0").unwrap());
// allocate `outbound` sink and `inbound` stream
let (outbound, inbound, addr) = bind_udp_bytes(addr).await;
println!("Listening on {:?}", addr);After parsing the command line arguments we set up some Rust-based networking. Specifically, for either client or server roles we will need to allocate a UDP socket that is used for both sending and receiving messages. We do this by calling the async bind_udp_bytes function, which is defined in the hydroflow/src/util module. As an async function it returns a Future, so requires appending .await; the function returns a triple of type (UdpSink, UdpSource, SocketAddr). The first two are the types that we'll use in Hydroflow to send and receive messages, respectively. (Note: your IDE might expand out the UdpSink and UdpSource traits to their more verbose definitions. That is fine; you can ignore those.) The SocketAddr is there in case you specified port 0 in your addr argument, in which case this return value tells you what port the OS has assigned for you.
All that's left is to fire up the code for the appropriate role!
match opts.role {
Role::Server => {
run_server(outbound, inbound, opts).await;
}
Role::Client => {
run_client(outbound, inbound, opts).await;
}
}
}protocol.rs
As a design pattern, it is natural in distributed Hydroflow programs to define various message types in a protocol.rs file with structures shared for use by all the Hydroflow logic across roles. In this simple example, we define only one message type: EchoMsg, and a simple struct with two fields: payload and ts (timestamp). The payload field is a string, and the ts field is a DateTime<Utc>, which is a type from the chrono crate. Note the various derived traits on EchoMsg—specifically Serialize and Deserialize—these are required for structs that we send over the network.
use chrono::prelude::*;
use serde::{Deserialize, Serialize};
#[derive(PartialEq, Clone, Serialize, Deserialize, Debug)]
pub struct EchoMsg {
pub payload: String,
pub ts: DateTime<Utc>,
}server.rs
Things get interesting when we look at the run_server function. This function is the main entry point for the server. It takes as arguments the outbound and inbound sockets from main, and the Opts (which are ignored).
After printing a cheery message, we get into the Hydroflow code for the server, consisting of three short pipelines.
use crate::protocol::EchoMsg;
use chrono::prelude::*;
use hydroflow::hydroflow_syntax;
use hydroflow::scheduled::graph::Hydroflow;
use hydroflow::util::{UdpSink, UdpStream};
use std::net::SocketAddr;
pub(crate) async fn run_server(outbound: UdpSink, inbound: UdpStream, _opts: crate::Opts) {
println!("Server live!");
let mut flow: Hydroflow = hydroflow_syntax! {
// Define a shared inbound channel
inbound_chan = source_stream_serde(inbound) -> tee();
// Print all messages for debugging purposes
inbound_chan[0]
-> for_each(|(msg, addr): (EchoMsg, SocketAddr)| println!("{}: Got {:?} from {:?}", Utc::now(), msg, addr));
// Echo back the Echo messages with updated timestamp
inbound_chan[1]
-> map(|(EchoMsg {payload, ..}, addr)| (EchoMsg { payload, ts: Utc::now() }, addr) ) -> dest_sink_serde(outbound);
};
// run the server
flow.run_async().await;
}Lets take the Hydroflow code one statement at a time.
The first pipeline, inbound_chan uses a source operator we have not seen before, source_stream_serde(). This is a streaming source like source_stream, but for network streams. It takes a UdpSource as an argument, and has a particular output type: a stream of (T, SocketAddr) pairs where T is some type that implements the Serialize and Deserialize traits (together known as "serde"), and SocketAddr is the network address of the sender of the item. In this case, T is EchoMsg, which we defined in protocol.rs, and the SocketAddr is the address of the client that sent the message. We pipe the result into a tee() for reuse.
The second pipeline is a simple for_each to print the messages received at the server.
The third and final pipeline constructs a response EchoMsg with the local timestamp copied in. It then pipes the result into a dest_XXX operator—the first that we've seen! A dest is the opposite of a source_XXX operator: it can go at the end of a pipeline and sends data out on a tokio channel. The specific operator used here is dest_sink_serde(). This is a dest operator like dest_sink, but for network streams. It takes a UdpSink as an argument, and requires a particular input type: a stream of (T, SocketAddr) pairs where T is some type that implements the Serialize and Deserialize traits, and SocketAddr is the network address of the destination. In this case, T is once again EchoMsg, and the SocketAddr is the address of the client that sent the original message.
The remaining line of code runs the server. The run_async() function is a method on the Hydroflow type. It is an async function, so we append .await to the call. The program will block on this call until the server is terminated.
client.rs
The client begins by making sure the user specified a server address at the command line. After printing a message to the terminal, it constructs a hydroflow graph.
Again, we start the hydroflow code defining shared inbound and outbound channels. The code here is simplified compared
to the server because the inbound_chan and outbound_chan are each referenced only once, so they do not require tee or merge operators, respectively (they have been commented out).
The inbound_chan drives a pipeline that prints messages to the screen.
Only the last pipeline is novel for us by now. It uses another new source operator source_stdin(), which does what you might expect: it streams lines of text as they arrive from stdin (i.e. as they are typed into a terminal). It then uses a map to construct an EchoMsg with each line of text and the current timestamp. The result is piped into a sink operator dest_sink_serde(), which sends the message to the server.
The client logic ends by launching the flow graph with flow.run_async().await.unwrap().
use crate::protocol::EchoMsg;
use crate::Opts;
use chrono::prelude::*;
use hydroflow::hydroflow_syntax;
use hydroflow::util::{UdpSink, UdpStream};
use std::net::SocketAddr;
pub(crate) async fn run_client(outbound: UdpSink, inbound: UdpStream, opts: Opts) {
// server_addr is required for client
let server_addr = opts.server_addr.expect("Client requires a server address");
println!("Client live!");
let mut flow = hydroflow_syntax! {
// Define shared inbound and outbound channels
inbound_chan = source_stream_serde(inbound)
// -> tee() // commented out since we only use this once in the client template
;
outbound_chan = // merge() -> // commented out since we only use this once in the client template
dest_sink_serde(outbound);
// Print all messages for debugging purposes
inbound_chan
-> for_each(|(m, a): (EchoMsg, SocketAddr)| println!("{}: Got {:?} from {:?}", Utc::now(), m, a));
// take stdin and send to server as an Message::Echo
source_stdin() -> map(|l| (EchoMsg{ payload: l.unwrap(), ts: Utc::now(), }, server_addr) )
-> outbound_chan;
};
flow.run_async().await.unwrap();
}Running the example
As described in the README.md file, we can run the server in one terminal, and the client in another. The server will print the messages it receives, and the client will print the messages it receives back from the server. The client and servers' `--server-addr' arguments need to match or this won't work!
Fire up the server in terminal 1:
% cargo run -p hydroflow --example echoserver -- --role server --addr localhost:12347
Then start the client in terminal 2 and type some messages!
% cargo run -p hydroflow --example echoserver -- --role client --server-addr localhost:12347
Listening on 127.0.0.1:54532
Connecting to server at 127.0.0.1:12347
Client live!
This is a test
2022-12-15 05:40:11.258052 UTC: Got Echo { payload: "This is a test", ts: 2022-12-15T05:40:11.257145Z } from 127.0.0.1:12347
This is the rest
2022-12-15 05:40:14.025216 UTC: Got Echo { payload: "This is the rest", ts: 2022-12-15T05:40:14.023577Z } from 127.0.0.1:12347
And have a look back at the server console!
Listening on 127.0.0.1:12347
Server live!
2022-12-15 05:40:11.256640 UTC: Got Echo { payload: "This is a test", ts: 2022-12-15T05:40:11.254207Z } from 127.0.0.1:54532
2022-12-15 05:40:14.023363 UTC: Got Echo { payload: "This is the rest", ts: 2022-12-15T05:40:14.020897Z } from 127.0.0.1:54532
Networked Services 2: Chat Server
In this example we cover:
- Multiple message types and the
demuxoperator.- A broadcast pattern via the
cross_joinoperator.- One-time bootstrapping pipelines
- A "gated buffer" pattern via
cross_joinwith a single-object input.
Our previous echo server example was admittedly simplistic. In this example, we'll build something a bit more useful: a simple chat server. We will again have two roles: a Client and a Server. Clients will register their presence with the Server, which maintains a list of clients. Each Client sends messages to the Server, which will then broadcast those messages to all other clients.
main.rs
The main.rs file here is very similar to that of the echo server, just with two new command-line arguments: one called name for a "nickname" in the chatroom, and another optional argument graph for printing a dataflow graph if desired. To follow along, you can copy the contents of this file into the src/main.rs file of your template.
use clap::{Parser, ValueEnum};
use client::run_client;
use hydroflow::tokio;
use hydroflow::util::{bind_udp_bytes, ipv4_resolve};
use server::run_server;
use std::net::SocketAddr;
mod client;
mod protocol;
mod server;
#[derive(Clone, ValueEnum, Debug)]
enum Role {
Client,
Server,
}
#[derive(Clone, ValueEnum, Debug)]
enum GraphType {
Mermaid,
Dot,
Json,
}
#[derive(Parser, Debug)]
struct Opts {
#[clap(long)]
name: String,
#[clap(value_enum, long)]
role: Role,
#[clap(long, value_parser = ipv4_resolve)]
client_addr: Option<SocketAddr>,
#[clap(long, value_parser = ipv4_resolve)]
server_addr: Option<SocketAddr>,
#[clap(value_enum, long)]
graph: Option<GraphType>,
}
#[tokio::main]
async fn main() {
let opts = Opts::parse();
// if no addr was provided, we ask the OS to assign a local port by passing in "localhost:0"
let addr = opts
.addr
.unwrap_or_else(|| ipv4_resolve("localhost:0").unwrap());
// allocate `outbound` sink and `inbound` stream
let (outbound, inbound, addr) = bind_udp_bytes(addr).await;
println!("Listening on {:?}", addr);
match opts.role {
Role::Client => {
run_client(outbound, inbound, opts).await;
}
Role::Server => {
run_server(outbound, inbound, opts).await;
}
}
}protocol.rs
Our protocol file here expands upon what we saw with the echoserver by defining multiple message types.
Replace the template contents of src/protocol.rs with the following:
use chrono::prelude::*;
use serde::{Deserialize, Serialize};
#[derive(PartialEq, Eq, Clone, Serialize, Deserialize, Debug)]
pub enum Message {
ConnectRequest,
ConnectResponse,
ChatMsg {
nickname: String,
message: String,
ts: DateTime<Utc>,
},
}Note how we use a single Rust enum to represent all varieties of message types; this allows us to handle Messages of different types with a single Rust network channel. We will use the demux operator to separate out these different message types on the receiving end.
The ConnectRequest and ConnectResponse messages have no payload;
the address of the sender and the type of the message will be sufficient information. The ChatMsg message type has a nickname field, a message field, and a ts
field for the timestamp. Once again we use the chrono crate to represent timestamps.
server.rs
The chat server is nearly as simple as the echo server. The main differences are (a) we need to handle multiple message types, (b) we need to keep track of the list of clients, and (c) we need to broadcast messages to all clients.
To follow along, replace the contents of src/server.rs with the code below:
use crate::{GraphType, Opts};
use hydroflow::util::{UdpSink, UdpStream};
use crate::protocol::Message;
use hydroflow::hydroflow_syntax;
use hydroflow::scheduled::graph::Hydroflow;
pub(crate) async fn run_server(outbound: UdpSink, inbound: UdpStream, opts: Opts) {
println!("Server live!");
let mut df: Hydroflow = hydroflow_syntax! {
// Define shared inbound and outbound channels
outbound_chan = merge() -> dest_sink_serde(outbound);
inbound_chan = source_stream_serde(inbound)
-> demux(|(msg, addr), var_args!(clients, msgs, errs)|
match msg {
Message::ConnectRequest => clients.give(addr),
Message::ChatMsg {..} => msgs.give(msg),
_ => errs.give(msg),
}
);
clients = inbound_chan[clients] -> tee();
inbound_chan[errs] -> for_each(|m| println!("Received unexpected message type: {:?}", m));After a short prelude, we have the Hydroflow code near the top of run_server(). It begins by defining outbound_chan as a merged destination sink for network messages. Then we get to the
more interesting inbound_chan definition.
The inbound channel is a source stream that will carry many
types of Messages. We use the demux operator to partition the stream objects into three channels. The clients channel
will carry the addresses of clients that have connected to the server. The msgs channel will carry the ChatMsg messages that clients send to the server.
The errs channel will carry any other messages that clients send to the server.
Note the structure of the demux operator: it takes a closure on
(Message, SocketAddr) pairs, and a variadic tuple (var_args!) of output channel names—in this case clients, msgs, and errs. The closure is basically a big
Rust pattern match, with one arm for each output channel name given in the variadic tuple. Note
that the different output channels can have different-typed messages! Note also that we destructure the incoming Message types into tuples of fields. (If we didn't we'd either have to write boilerplate code for each message type in every downstream pipeline, or face Rust's dreaded refutable pattern error!)
The remainder of the server consists of two independent pipelines, the code to print out the flow graph,
and the code to run the flow graph. To follow along, paste the following into the bottom of your src/server.rs file:
// Pipeline 1: Acknowledge client connections
clients[0] -> map(|addr| (Message::ConnectResponse, addr)) -> [0]outbound_chan;
// Pipeline 2: Broadcast messages to all clients
broadcast = cross_join() -> [1]outbound_chan;
inbound_chan[msgs] -> [0]broadcast;
clients[1] -> [1]broadcast;
};
if let Some(graph) = graph {
let serde_graph = df
.meta_graph()
.expect("No graph found, maybe failed to parse.");
match graph {
GraphType::Mermaid => {
println!("{}", serde_graph.to_mermaid());
}
GraphType::Dot => {
println!("{}", serde_graph.to_dot())
}
GraphType::Json => {
unimplemented!();
// println!("{}", serde_graph.to_json())
}
}
}
df.run_async().await.unwrap();
}The first pipeline is one line long,
and is responsible for acknowledging requests from clients: it takes the address of the incoming Message::ConnectRequest
and sends a ConnectResponse back to that address. The second pipeline is responsible for broadcasting
all chat messages to all clients. This all-to-all pairing corresponds to the notion of a cartesian product
or cross_join in Hydroflow. The cross_join operator takes two input
channels and produces a single output channel with a tuple for each pair of inputs, in this case it produces
(Message, SocketAddr) pairs. Conveniently, that is exactly the structure needed for sending to the outbound_chan sink!
We call the cross-join pipeline broadcast because it effectively broadcasts all messages to all clients.
The mermaid graph for the server is below. The three branches of the demux are very clear toward the top. Note also the tee of the clients channel
for both ClientResponse and broadcasting, and the merge of all outbound messages into dest_sink_serde.
%%{init: {'theme': 'base', 'themeVariables': {'clusterBkg':'#ddd'}}}%%
flowchart TD
classDef pullClass fill:#02f,color:#fff,stroke:#000
classDef pushClass fill:#ff0,stroke:#000
linkStyle default stroke:#aaa,stroke-width:4px,color:red,font-size:1.5em;
subgraph "sg_1v1 stratum 0"
7v1[\"(7v1) <tt>map(| addr | (Message :: ConnectResponse, addr))</tt>"/]:::pullClass
8v1[\"(8v1) <tt>cross_join()</tt>"/]:::pullClass
1v1[\"(1v1) <tt>merge()</tt>"/]:::pullClass
2v1[/"(2v1) <tt>dest_sink_serde(outbound)</tt>"\]:::pushClass
7v1--0--->1v1
8v1--1--->1v1
1v1--->2v1
end
subgraph "sg_2v1 stratum 0"
3v1[\"(3v1) <tt>source_stream_serde(inbound)</tt>"/]:::pullClass
4v1[/"(4v1) <tt>demux(| (msg, addr), var_args! (clients, msgs, errs) | match msg<br>{<br> Message :: ConnectRequest => clients.give(addr), Message :: ChatMsg { .. }<br> => msgs.give(msg), _ => errs.give(msg),<br>})</tt>"\]:::pushClass
5v1[/"(5v1) <tt>tee()</tt>"\]:::pushClass
6v1[/"(6v1) <tt>for_each(| m | println! ("Received unexpected message type: {:?}", m))</tt>"\]:::pushClass
3v1--->4v1
4v1--clients--->5v1
4v1--errs--->6v1
end
4v1--msgs--->10v1
5v1--0--->9v1
5v1--1--->11v1
9v1["(9v1) <tt>handoff</tt>"]:::otherClass
9v1--->7v1
10v1["(10v1) <tt>handoff</tt>"]:::otherClass
10v1--0--->8v1
11v1["(11v1) <tt>handoff</tt>"]:::otherClass
11v1--1--->8v1
client.rs
The chat client is not very different from the echo server client, with two new design patterns:
- a degenerate
source_iterpipeline that runs once as a "bootstrap" in the first tick - the use of
cross_joinas a "gated buffer" to postpone sending messages.
We also include a Rust helper routine pretty_print_msg for formatting output.
The prelude of the file is almost the same as the echo server client, with the addition of a crate for
handling colored text output. This is followed by the pretty_print_msg function, which is fairly self-explanatory.
To follow along, start by replacing the contents of src/client.rs with the following:
use crate::protocol::Message;
use crate::{GraphType, Opts};
use chrono::prelude::*;
use hydroflow::hydroflow_syntax;
use hydroflow::util::{UdpSink, UdpStream};
use chrono::Utc;
use colored::Colorize;
fn pretty_print_msg(msg: Message) {
if let Message::ChatMsg {
nickname,
message,
ts,
} = msg
{
println!(
"{} {}: {}",
ts.with_timezone(&Local)
.format("%b %-d, %-I:%M:%S")
.to_string()
.truecolor(126, 126, 126)
.italic(),
nickname.green().italic(),
message,
);
}
}This brings us to the run_client function. As in run_server we begin by ensuring the server address
is supplied. We then have the hydroflow code starting with a standard pattern of a merged outbound_chan,
and a demuxed inbound_chan. The client handles only two inbound Message types: Message::ConnectResponse and Message::ChatMsg.
Paste the following to the bottom of src/client.rs:
pub(crate) async fn run_client(outbound: UdpSink, inbound: UdpStream, opts: Opts) {
// server_addr is required for client
let server_addr = opts.server_addr.expect("Client requires a server address");
println!("Client live!");
let mut hf = hydroflow_syntax! {
// set up channels
outbound_chan = merge() -> dest_sink_serde(outbound);
inbound_chan = source_stream_serde(inbound) -> map(|(m, _)| m)
-> demux(|m, var_args!(acks, msgs, errs)|
match m {
Message::ConnectResponse => acks.give(m),
Message::ChatMsg {..} => msgs.give(m),
_ => errs.give(m),
}
);
inbound_chan[errs] -> for_each(|m| println!("Received unexpected message type: {:?}", m));The core logic of the client consists of three dataflow pipelines shown below. Paste this into the
bottom of your src/client.rs file.
// send a single connection request on startup
source_iter([()]) -> map(|_m| (Message::ConnectRequest, server_addr)) -> [0]outbound_chan;
// take stdin and send to server as a msg
// the cross_join serves to buffer msgs until the connection request is acked
msg_send = cross_join() -> map(|(msg, _)| (msg, server_addr)) -> [1]outbound_chan;
lines = source_stdin()
-> map(|l| Message::ChatMsg {
nickname: opts.name.clone(),
message: l.unwrap(),
ts: Utc::now()})
-> [0]msg_send;
inbound_chan[acks] -> [1]msg_send;
// receive and print messages
inbound_chan[msgs] -> for_each(pretty_print_msg);
};-
The first pipeline is the "bootstrap" alluded to above. It starts with
source_iteroperator that emits a single, opaque "unit" (()) value. This value is available when the client begins, which means this pipeline runs once, immediately on startup, and generates a singleConnectRequestmessage which is sent to the server. -
The second pipeline reads from
source_stdinand sends messages to the server. It differs from our echo-server example in the use of across_joinwithinbound_chan[acks]. This cross-join is similar to that of the server: it forms pairs between all messages and all servers that send aConnectResponseack. In principle this means that the client is broadcasting each message to all servers. In practice, however, the client establishes at most one connection to a server. Hence over time, this pipeline starts with zeroConnectResponses and is sending no messages; subsequently it receives a singleConnectResponseand starts sending messages. Thecross_joinis thus effectively a buffer for messages, and a "gate" on that buffer that opens when the client receives its soleConnectResponse. -
The final pipeline simply pretty-prints the messages received from the server.
Finish up the file by pasting the code below for optionally generating the graph and running the flow:
// optionally print the dataflow graph
if let Some(graph) = opts.graph {
let serde_graph = hf
.meta_graph()
.expect("No graph found, maybe failed to parse.");
match graph {
GraphType::Mermaid => {
println!("{}", serde_graph.to_mermaid());
}
GraphType::Dot => {
println!("{}", serde_graph.to_dot())
}
GraphType::Json => {
unimplemented!();
}
}
}
hf.run_async().await.unwrap();
}The client's mermaid graph looks a bit different than the server's, mostly because it routes some data to the screen rather than to an outbound network channel.
%%{init: {'theme': 'base', 'themeVariables': {'clusterBkg':'#ddd'}}}%%
flowchart TD
classDef pullClass fill:#02f,color:#fff,stroke:#000
classDef pushClass fill:#ff0,stroke:#000
linkStyle default stroke:#aaa,stroke-width:4px,color:red,font-size:1.5em;
subgraph "sg_1v1 stratum 0"
7v1[\"(7v1) <tt>source_iter([()])</tt>"/]:::pullClass
8v1[\"(8v1) <tt>map(| _m | (Message :: ConnectRequest, server_addr))</tt>"/]:::pullClass
11v1[\"(11v1) <tt>source_stdin()</tt>"/]:::pullClass
12v1[\"(12v1) <tt>map(| l | Message :: ChatMsg<br>{ nickname : opts.name.clone(), message : l.unwrap(), ts : Utc :: now() })</tt>"/]:::pullClass
9v1[\"(9v1) <tt>cross_join()</tt>"/]:::pullClass
10v1[\"(10v1) <tt>map(| (msg, _) | (msg, server_addr))</tt>"/]:::pullClass
1v1[\"(1v1) <tt>merge()</tt>"/]:::pullClass
2v1[/"(2v1) <tt>dest_sink_serde(outbound)</tt>"\]:::pushClass
7v1--->8v1
8v1--0--->1v1
11v1--->12v1
12v1--0--->9v1
9v1--->10v1
10v1--1--->1v1
1v1--->2v1
end
subgraph "sg_2v1 stratum 0"
3v1[\"(3v1) <tt>source_stream_serde(inbound)</tt>"/]:::pullClass
4v1[/"(4v1) <tt>map(| (m, _) | m)</tt>"\]:::pushClass
5v1[/"(5v1) <tt>demux(| m, var_args! (acks, msgs, errs) | match m<br>{<br> Message :: ConnectResponse => acks.give(m), Message :: ChatMsg { .. } =><br> msgs.give(m), _ => errs.give(m),<br>})</tt>"\]:::pushClass
6v1[/"(6v1) <tt>for_each(| m | println! ("Received unexpected message type: {:?}", m))</tt>"\]:::pushClass
13v1[/"(13v1) <tt>for_each(pretty_print_msg)</tt>"\]:::pushClass
3v1--->4v1
4v1--->5v1
5v1--errs--->6v1
5v1--msgs--->13v1
end
5v1--acks--->14v1
14v1["(14v1) <tt>handoff</tt>"]:::otherClass
14v1--1--->9v1
Running the example
As described in hydroflow/hydroflow/example/chat/README.md, we can run the server in one terminal, and run clients in additional terminals.
The client and server need to agree on server-addr or this won't work!
Fire up the server in terminal 1:
% cargo run -p hydroflow --example chat -- --name "_" --role server --server-addr 127.0.0.1:12347
Start client "alice" in terminal 2 and type some messages, and you'll see them echoed back to you. This will appear in colored fonts in most terminals (but unfortunately not in this markdown-based book!)
% cargo run -p hydroflow --example chat -- --name "alice" --role client --server-addr 127.0.0.1:12347
Listening on 127.0.0.1:50617
Connecting to server at 127.0.0.1:12347
Client live!
Hello (hello hello) ... is there anybody in here?
Dec 13, 12:04:34 alice: Hello (hello hello) ... is there anybody in here?
Just nod if you can hear me.
Dec 13, 12:04:58 alice: Just nod if you can hear me.
Is there anyone home?
Dec 13, 12:05:01 alice: Is there anyone home?
Now start client "bob" in terminal 3, and notice how he instantly receives the backlog of Alice's messages from the server's cross_join.
(The messages may not be printed in the same order as they were timestamped! The cross_join operator is not guaranteed to preserve order, nor
is the udp network. Fixing these issues requires extra client logic that we leave as an exercise to the reader.)
% cargo run -p hydroflow --example chat -- --name "bob" --role client --server-addr 127.0.0.1:12347
Listening on 127.0.0.1:63018
Connecting to server at 127.0.0.1:12347
Client live!
Dec 13, 12:05:01 alice: Is there anyone home?
Dec 13, 12:04:58 alice: Just nod if you can hear me.
Dec 13, 12:04:34 alice: Hello (hello hello) ... is there anybody in here?
Now in terminal 3, Bob can respond:
*nods*
Dec 13, 12:05:05 bob: *nods*
and if we go back to terminal 2 we can see that Alice gets the message too:
Dec 13, 12:05:05 bob: *nods*
Hydroflow Surface Syntax
The natural way to write a Hydroflow program is using the Surface Syntax documented here.
It is a chained Iterator-style syntax of operators built into Hydroflow that should be sufficient
for most uses. If you want lower-level access you can work with the Core API documented in the Architecture section.
In this chapter we go over the syntax piece by piece: how to embed surface syntax in Rust and how to specify flows, which consist of data sources flowing through operators.
As a teaser, here is a Rust/Hydroflow "HELLO WORLD" program:
#![allow(unused)] fn main() { use hydroflow::hydroflow_syntax; pub fn test_hello_world() { let mut df = hydroflow_syntax! { source_iter(vec!["hello", "world"]) -> map(|x| x.to_uppercase()) -> for_each(|x| println!("{}", x)); }; df.run_available(); } }
Embedding a Flow in Rust
Hydroflow's surface syntax is typically used within a Rust program. (An interactive client and/or external language bindings are TBD.)
The surface syntax is embedded into Rust via a macro as follows
#![allow(unused)] fn main() { use hydroflow::hydroflow_syntax; pub fn example() { let mut flow = hydroflow_syntax! { // Hydroflow Surface Syntax goes here }; } }
The resulting flow object is of type Hydroflow.
Flow Syntax
Flows consist of named operators that are connected via flow edges denoted by ->. The example below
uses the source_iter operator to generate two strings from a Rust vec, the
map operator to apply some Rust code to uppercase each string, and the for_each
operator to print each string to stdout.
source_iter(vec!["Hello", "world"])
-> map(|x| x.to_uppercase()) -> for_each(|x| println!("{}", x));Flows can be assigned to variable names for convenience. E.g, the above can be rewritten as follows:
source_iter(vec!["Hello", "world"]) -> upper_print;
upper_print = map(|x| x.to_uppercase()) -> for_each(|x| println!("{}", x));Note that the order of the statements (lines) doesn't matter. In this example, upper_print is
referenced before it is assigned, and that is completely OK and better matches the flow of
data, making the program more understandable.
Operators with Multiple Ports
Some operators have more than one input port that can be referenced by ->. For example merge
merges the contents of many flows, so it can have an abitrary number of input ports. Some operators have multiple outputs, notably tee,
which has an arbitrary number of outputs.
In the syntax, we optionally distinguish input ports via an indexing prefix number
in square brackets before the name (e.g. [0]my_join and [1]my_join). We
can distinguish output ports by an indexing suffix (e.g. my_tee[0]).
Here is an example that tees one flow into two, handles each separately, and then merges them to print out the contents in both lowercase and uppercase:
my_tee = source_iter(vec!["Hello", "world"]) -> tee();
my_tee -> map(|x| x.to_uppercase()) -> my_merge;
my_tee -> map(|x| x.to_lowercase()) -> my_merge;
my_merge = merge() -> for_each(|x| println!("{}", x));merge() and tee() treat all their input/outputs the same, so we omit the indexing.
Here is a visualization of the flow that was generated:
%%{init:{'theme':'base','themeVariables':{'clusterBkg':'#ddd','clusterBorder':'#888'}}}%%
flowchart TD
classDef pullClass fill:#02f,color:#fff,stroke:#000
classDef pushClass fill:#ff0,stroke:#000
linkStyle default stroke:#aaa,stroke-width:4px,color:red,font-size:1.5em;
subgraph sg_1v1 ["sg_1v1 stratum 0"]
1v1[\"(1v1) <tt>source_iter(vec! ["Hello", "world"])</tt>"/]:::pullClass
2v1[/"(2v1) <tt>tee()</tt>"\]:::pushClass
1v1--->2v1
subgraph sg_1v1_var_my_tee ["var <tt>my_tee</tt>"]
1v1
2v1
end
end
subgraph sg_2v1 ["sg_2v1 stratum 0"]
3v1[\"(3v1) <tt>map(| x : & str | x.to_uppercase())</tt>"/]:::pullClass
4v1[\"(4v1) <tt>map(| x : & str | x.to_lowercase())</tt>"/]:::pullClass
5v1[\"(5v1) <tt>merge()</tt>"/]:::pullClass
6v1[/"(6v1) <tt>for_each(| x | println! ("{}", x))</tt>"\]:::pushClass
3v1--0--->5v1
4v1--1--->5v1
5v1--->6v1
subgraph sg_2v1_var_my_merge ["var <tt>my_merge</tt>"]
5v1
6v1
end
end
2v1--0--->7v1
2v1--1--->8v1
7v1["(7v1) <tt>handoff</tt>"]:::otherClass
7v1--->3v1
8v1["(8v1) <tt>handoff</tt>"]:::otherClass
8v1--->4v1
Hydroflow compiled this flow into two subgraphs called compiled components, connected by handoffs. You can ignore these details unless you are interested in low-level performance tuning; they are explained in the discussion of in-out trees.
A note on assigning flows with multiple ports
TODO: Need to document the port numbers for variables assigned to tree- or dag-shaped flows
The context object
Closures inside surface syntax operators have access to a special context object which provides
access to scheduling, timing, and state APIs. The object is accessible as a shared reference
(&Context) via the special name context.
Here is the full API documentation for Context.
source_iter([()])
-> for_each(|()| println!("Current tick: {}, stratum: {}", context.current_tick(), context.current_stratum()));
// Current tick: 0, stratum: 0Data Sources and Sinks in Rust
Any useful flow requires us to define sources of data, either generated computationally or received from and outside environment via I/O.
source_iter
A flow can receive data from a Rust collection object via the source_iter operator, which takes the
iterable collection as an argument and passes the items down the flow.
For example, here we iterate through a vector of usize items and push them down the flow:
source_iter(vec![0, 1]) -> ...The Hello, World example above uses this construct.
source_stream
More commonly, a flow should handle external data coming in asynchronously from a Tokio runtime.
One way to do this is with channels that allow Rust code to send data into the Hydroflow inputs.
The code below creates a channel for data of (Rust) type (usize, usize):
let (input_send, input_recv) = hydroflow::util::unbounded_channel::<(usize, usize)>();Under the hood this uses Tokio unbounded channels. Now in Rust we can now push data into the channel. E.g. for testing we can do it explicitly as follows:
input_send.send((0, 1)).unwrap()And in our Hydroflow syntax we can receive the data from the channel using the source_stream syntax and
pass it along a flow:
source_stream(input_recv) -> ...To put this together, let's revisit our Hello, World example from above with data sent in from outside the flow:
#![allow(unused)] fn main() { use hydroflow::hydroflow_syntax; let (input_send, input_recv) = hydroflow::util::unbounded_channel::<&str>(); let mut flow = hydroflow_syntax! { source_stream(input_recv) -> map(|x| x.to_uppercase()) -> for_each(|x| println!("{}", x)); }; input_send.send("Hello").unwrap(); input_send.send("World").unwrap(); flow.run_available(); }
TODO: add source_stream_serde
Hydroflow's Operators
In our previous examples we made use of some of Hydroflow's operators. Here we document each operator in more detail. Most of these operators are based on the Rust equivalents for iterators; see the Rust documentation.
anti_join
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 2 | -> [<input_port>]anti_join() -> | exactly 1 | Blocking |
Input port names:
pos(streaming),neg(blocking)
2 input streams the first of type (K, T), the second of type K, with output type (K, T)
For a given tick, computes the anti-join of the items in the input
streams, returning items in the pos input that do not have matching keys
in the neg input.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print ("elephant", 3) source_iter(vec![("dog", 1), ("cat", 2), ("elephant", 3)]) -> [pos]diff; source_iter(vec!["dog", "cat", "gorilla"]) -> [neg]diff; diff = anti_join() -> for_each(|v: (_, _)| println!("{}, {}", v.0, v.1)); // elephant 3 }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
batch
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> batch(A, B) -> | exactly 1 | Streaming |
1 input stream, 1 output stream
Arguments: First argument is the maximum batch size that batch() will buffer up before completely releasing the batch. The second argument is the receive end of a tokio channel that signals when to release the batch downstream.
Given a Stream
created in Rust code, batch
is passed the receive end of the channel and when receiving any element
will pass through all received inputs to the output unchanged.
#![allow(unused)] fn main() { let (tx, rx) = hydroflow::util::unbounded_channel::<()>(); // Will print 0, 1, 2, 3, 4 each on a new line just once. let mut df = hydroflow::hydroflow_syntax! { repeat_iter(0..5) -> batch(10, rx) -> for_each(|x| { println!("{x}"); }); }; tx.send(()).unwrap(); df.run_available(); }
cross_join
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 2 | -> [<input_port>]cross_join() -> | exactly 1 | Streaming |
Input port names:
0(streaming),1(streaming)
2 input streams of type S and T, 1 output stream of type (S, T)
Forms the cross-join (Cartesian product) of the items in the input streams, returning all tupled pairs.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print all 4 pairs of emotion and animal source_iter(vec!["happy", "sad"]) -> [0]my_join; source_iter(vec!["dog", "cat"]) -> [1]my_join; my_join = cross_join() -> for_each(|(v1, v2)| println!("({}, {})", v1, v2)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
cross_join can also be provided with one or two generic lifetime persistence arguments
in the same was as join, see join's documentation for more info.
cross_join also accepts one type argument that controls how the join state is built up. This (currently) allows switching between a SetUnion and NonSetUnion implementation.
For example:
join::<HalfSetJoinState>();
join::<HalfMultisetJoinState>();
#![allow(unused)] fn main() { let (input_send, input_recv) = hydroflow::util::unbounded_channel::<&str>(); let mut flow = hydroflow::hydroflow_syntax! { my_join = cross_join::<'tick>(); source_iter(["hello", "bye"]) -> [0]my_join; source_stream(input_recv) -> [1]my_join; my_join -> for_each(|(s, t)| println!("({}, {})", s, t)); }; input_send.send("oakland").unwrap(); flow.run_tick(); input_send.send("san francisco").unwrap(); flow.run_tick(); }
Prints only "(hello, oakland)" and "(bye, oakland)". The source_iter is only included in
the first tick, then forgotten.
demux
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> demux(A)[<output_port>] -> | at least 2 | Streaming |
Output port names: Variadic, as specified in arguments.
Arguments: A Rust closure, the first argument is a received item and the second argument is a variadic
var_args!tuple list where each item name is an output port.
Takes the input stream and allows the user to determine what elemnt(s) to deliver to any number of output streams.
Note: Downstream operators may need explicit type annotations.
Note: The
Pusheratortrait is automatically imported to enable the.give(...)method.
Note: The closure has access to the
contextobject.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { my_demux = source_iter(1..=100) -> demux(|v, var_args!(fzbz, fizz, buzz, vals)| match (v % 3, v % 5) { (0, 0) => fzbz.give(v), (0, _) => fizz.give(v), (_, 0) => buzz.give(v), (_, _) => vals.give(v), } ); my_demux[fzbz] -> for_each(|v| println!("{}: fizzbuzz", v)); my_demux[fizz] -> for_each(|v| println!("{}: fizz", v)); my_demux[buzz] -> for_each(|v| println!("{}: buzz", v)); my_demux[vals] -> for_each(|v| println!("{}", v)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
dest_file
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> dest_file(A, B) | exactly 0 | Streaming |
0 input streams, 1 output stream
Arguments: (1) An
AsRef<Path>for a file to write to, and (2) a boolappend.
Consumes Strings by writing them as lines to a file. The file will be created if it doesn't
exist. Lines will be appended to the file if append is true, otherwise the file will be
truncated before lines are written.
Note this operator must be used within a Tokio runtime.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_iter(1..=10) -> map(|n| format!("Line {}", n)) -> dest_file("dest.txt", false); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
dest_sink
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> dest_sink(A) | exactly 0 | Streaming |
Arguments: An async
Sink.
Consumes items by sending them to an async Sink.
A Sink is a thing into which values can be sent, asynchronously. For example, sending items
into a bounded channel.
Note this operator must be used within a Tokio runtime.
#[tokio::main(flavor = "current_thread")] async fn main() { // In this example we use a _bounded_ channel for our `Sink`. This is for demonstration only, // instead you should use [`hydroflow::util::unbounded_channel`]. A bounded channel results in // `Hydroflow` buffering items internally instead of within the channel. (We can't use // unbounded here since unbounded channels are synchonous to write to and therefore not // `Sink`s.) let (send, recv) = tokio::sync::mpsc::channel::<usize>(5); // `PollSender` adapts the send half of the bounded channel into a `Sink`. let send = tokio_util::sync::PollSender::new(send); let mut flow = hydroflow::hydroflow_syntax! { source_iter(0..10) -> dest_sink(send); }; // Call `run_async()` to allow async events to propegate, run for one second. tokio::time::timeout(std::time::Duration::from_secs(1), flow.run_async()) .await .expect_err("Expected time out"); let mut recv = tokio_stream::wrappers::ReceiverStream::new(recv); // Only 5 elements received due to buffer size. // (Note that if we were using a multi-threaded executor instead of `current_thread` it would // be possible for more items to be added as they're removed, resulting in >5 collected.) let out: Vec<_> = hydroflow::util::ready_iter(&mut recv).collect(); assert_eq!(&[0, 1, 2, 3, 4], &*out); }
Sink is different from AsyncWrite.
Instead of discrete values we send arbitrary streams of bytes into an AsyncWrite value. For
example, writings a stream of bytes to a file, a socket, or stdout.
To handle those situations we can use a codec from tokio_util::codec.
These specify ways in which the byte stream is broken into individual items, such as with
newlines or with length delineation.
If we only want to write a stream of bytes without delineation we can use the BytesCodec.
In this example we use a duplex as our AsyncWrite with a
BytesCodec.
#[tokio::main] async fn main() { use bytes::Bytes; use tokio::io::AsyncReadExt; // Like a channel, but for a stream of bytes instead of discrete objects. let (asyncwrite, mut asyncread) = tokio::io::duplex(256); // Now instead handle discrete byte strings by length-encoding them. let sink = tokio_util::codec::FramedWrite::new(asyncwrite, tokio_util::codec::BytesCodec::new()); let mut flow = hydroflow::hydroflow_syntax! { source_iter([ Bytes::from_static(b"hello"), Bytes::from_static(b"world"), ]) -> dest_sink(sink); }; tokio::time::timeout(std::time::Duration::from_secs(1), flow.run_async()) .await .expect_err("Expected time out"); let mut buf = Vec::<u8>::new(); asyncread.read_buf(&mut buf).await.unwrap(); assert_eq!(b"helloworld", &*buf); }
dest_sink_serde
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> dest_sink_serde(A) | exactly 0 | Streaming |
Arguments: A serializing async
Sink.
Consumes (payload, addr) pairs by serializing the payload and sending the resulting pair to an async Sink.
Note this operator must be used within a Tokio runtime.
#![allow(unused)] fn main() { async fn serde_out() { let addr = hydroflow::util::ipv4_resolve("localhost:9000".into()).unwrap(); let (outbound, inbound, _) = hydroflow::util::bind_udp_bytes(addr).await; let remote = hydroflow::util::ipv4_resolve("localhost:9001".into()).unwrap(); let mut flow = hydroflow::hydroflow_syntax! { source_iter(vec![("hello".to_string(), 1), ("world".to_string(), 2)]) -> map (|m| (m, remote)) -> dest_sink_serde(outbound); }; flow.run_available(); } }
difference
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 2 | -> [<input_port>]difference() -> | exactly 1 | Blocking |
Input port names:
pos(streaming),neg(blocking)
2 input streams of the same type T, 1 output stream of type T
For a given tick, forms the set difference of the items in the input
streams, returning items in the pos input that are not found in the
neg input.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print "elephant" source_iter(vec!["dog", "cat", "elephant"]) -> [pos]diff; source_iter(vec!["dog", "cat", "gorilla"]) -> [neg]diff; diff = difference() -> for_each(|v| println!("{}", v)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
enumerate
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> enumerate() -> | exactly 1 | Streaming |
1 input stream of type
T, 1 output stream of type(usize, T)
For each item passed in, enumerate it with its index: (0, x_0), (1, x_1), etc.
enumerate can also be provided with one generic lifetime persistence argument, either
'tick or 'static, to specify if indexing resets. If 'tick is specified, indexing will
restart at zero at the start of each tick. Otherwise 'static (the default) will never reset
and count monotonically upwards.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_iter(vec!["hello", "world"]) -> enumerate() -> for_each(|(i, x)| println!("{}: {}", i, x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
filter
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> filter(A) -> | exactly 1 | Streaming |
Filter outputs a subsequence of the items it receives at its input, according to a Rust boolean closure passed in as an argument.
The closure receives a reference &T rather than an owned value T because filtering does
not modify or take ownership of the values. If you need to modify the values while filtering
use filter_map instead.
Note: The closure has access to the
contextobject.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_iter(vec!["hello", "world"]) -> filter(|x| x.starts_with('w')) -> for_each(|x| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
filter_map
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> filter_map(A) -> | exactly 1 | Streaming |
1 input stream, 1 output stream
An operator that both filters and maps. It yields only the items for which the supplied closure returns Some(value).
Note: The closure has access to the
contextobject.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_iter(vec!["1", "hello", "world", "2"]) -> filter_map(|s| s.parse().ok()) -> for_each(|x: usize| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
flat_map
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> flat_map(A) -> | exactly 1 | Streaming |
1 input stream, 1 output stream
Arguments: A Rust closure that handles an iterator
For each item i passed in, treat i as an iterator and map the closure to that
iterator to produce items one by one. The type of the input items must be iterable.
Note: The closure has access to the
contextobject.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print out each character of each word on a separate line source_iter(vec!["hello", "world"]) -> flat_map(|x| x.chars()) -> for_each(|x| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
flatten
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> flatten() -> | exactly 1 | Streaming |
1 input stream, 1 output stream
For each item i passed in, treat i as an iterator and produce its items one by one.
The type of the input items must be iterable.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print the numbers 1-6 without any nesting source_iter(vec![[1, 2], [3, 4], [5, 6]]) -> flatten() -> for_each(|x| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
fold
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> fold(A, B) -> | exactly 1 | Blocking |
1 input stream, 1 output stream
Arguments: an initial value, and a closure which itself takes two arguments: an 'accumulator', and an element. The closure returns the value that the accumulator should have for the next iteration.
Akin to Rust's built-in fold operator. Folds every element into an accumulator by applying a closure, returning the final result.
Note: The closure has access to the
contextobject.
fold can also be provided with one generic lifetime persistence argument, either
'tick or 'static, to specify how data persists. With 'tick, values will only be collected
within the same tick. With 'static, values will be remembered across ticks and will be
aggregated with pairs arriving in later ticks. When not explicitly specified persistence
defaults to 'static.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print `Reassembled vector [1,2,3,4,5]` source_iter([1,2,3,4,5]) -> fold::<'tick>(Vec::new(), |mut accum, elem| { accum.push(elem); accum }) -> for_each(|e| println!("Ressembled vector {:?}", e)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
for_each
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> for_each(A) | exactly 0 | Streaming |
1 input stream, 0 output streams
Arguments: a Rust closure
Iterates through a stream passing each element to the closure in the argument.
Note: The closure has access to the
contextobject.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_iter(vec!["Hello", "World"]) -> for_each(|x| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
group_by
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> group_by(A, B) -> | exactly 1 | Blocking |
An alias for keyed_fold.
identity
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> identity() -> | exactly 1 | Streaming |
1 input stream of type T, 1 output stream of type T
For each item passed in, pass it out without any change.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print "hello" and "world" on separate lines (in either order) source_iter(vec!["hello", "world"]) -> identity() -> for_each(|x| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
You can also supply a type parameter identity::<MyType>() to specify what items flow thru the
the pipeline. This can be useful for helping the compiler infer types.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // Use type parameter to ensure items are `i32`s. source_iter(0..10) -> identity::<i32>() -> for_each(|x| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
initialize
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 0 | initialize() -> | exactly 1 | Streaming |
0 input streams, 1 output stream
Arguments: None.
Emits a single unit () at the start of the first tick.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { initialize() -> for_each(|()| println!("This only runs one time!")); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
inspect
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> inspect(A) -> | exactly 1 | Streaming |
Arguments: A single closure
FnMut(&Item).
An operator which allows you to "inspect" each element of a stream without modifying it. The closure is called on a reference to each item. This is mainly useful for debugging as in the example below, and it is generally an anti-pattern to provide a closure with side effects.
Note: The closure has access to the
contextobject.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_iter([1, 2, 3, 4]) -> inspect(|&x| println!("{}", x)) -> null(); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
join
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 2 | -> [<input_port>]join() -> | exactly 1 | Streaming |
Input port names:
0(streaming),1(streaming)
2 input streams of type <(K, V1)> and <(K, V2)>, 1 output stream of type <(K, (V1, V2))>
Forms the equijoin of the tuples in the input streams by their first (key) attribute. Note that the result nests the 2nd input field (values) into a tuple in the 2nd output field.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print `(hello, (world, cleveland))` source_iter(vec![("hello", "world"), ("stay", "gold")]) -> [0]my_join; source_iter(vec![("hello", "cleveland")]) -> [1]my_join; my_join = join() -> for_each(|(k, (v1, v2))| println!("({}, ({}, {}))", k, v1, v2)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
join can also be provided with one or two generic lifetime persistence arguments, either
'tick or 'static, to specify how join data persists. With 'tick, pairs will only be
joined with corresponding pairs within the same tick. With 'static, pairs will be remembered
across ticks and will be joined with pairs arriving in later ticks. When not explicitly
specified persistence defaults to `static.
When two persistence arguments are supplied the first maps to port 0 and the second maps to
port 1.
When a single persistence argument is supplied, it is applied to both input ports.
When no persistence arguments are applied it defaults to 'static for both.
The syntax is as follows:
join(); // Or
join::<'static>();
join::<'tick>();
join::<'static, 'tick>();
join::<'tick, 'static>();
// etc.
Join also accepts one type argument that controls how the join state is built up. This (currently) allows switching between a SetUnion and NonSetUnion implementation. For example:
join::<HalfSetJoinState>();
join::<HalfMultisetJoinState>();
Examples
#![allow(unused)] fn main() { let (input_send, input_recv) = hydroflow::util::unbounded_channel::<(&str, &str)>(); let mut flow = hydroflow::hydroflow_syntax! { source_iter([("hello", "world")]) -> [0]my_join; source_stream(input_recv) -> [1]my_join; my_join = join::<'tick>() -> for_each(|(k, (v1, v2))| println!("({}, ({}, {}))", k, v1, v2)); }; input_send.send(("hello", "oakland")).unwrap(); flow.run_tick(); input_send.send(("hello", "san francisco")).unwrap(); flow.run_tick(); }
Prints out "(hello, (world, oakland))" since source_iter([("hello", "world")]) is only
included in the first tick, then forgotten.
#![allow(unused)] fn main() { let (input_send, input_recv) = hydroflow::util::unbounded_channel::<(&str, &str)>(); let mut flow = hydroflow::hydroflow_syntax! { source_iter([("hello", "world")]) -> [0]my_join; source_stream(input_recv) -> [1]my_join; my_join = join::<'static>() -> for_each(|(k, (v1, v2))| println!("({}, ({}, {}))", k, v1, v2)); }; input_send.send(("hello", "oakland")).unwrap(); flow.run_tick(); input_send.send(("hello", "san francisco")).unwrap(); flow.run_tick(); }
Prints out "(hello, (world, oakland))" and "(hello, (world, san francisco))" since the
inputs are peristed across ticks.
keyed_fold
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> keyed_fold(A, B) -> | exactly 1 | Blocking |
1 input stream of type
(K, V1), 1 output stream of type(K, V2). The output will have one tuple for each distinctK, with an accumulated value of typeV2.
If the input and output value types are the same and do not require initialization then use
keyed_reduce.
Arguments: two Rust closures. The first generates an initial value per group. The second itself takes two arguments: an 'accumulator', and an element. The second closure returns the value that the accumulator should have for the next iteration.
A special case of fold, in the spirit of SQL's GROUP BY and aggregation constructs. The input
is partitioned into groups by the first field, and for each group the values in the second
field are accumulated via the closures in the arguments.
Note: The closures have access to the
contextobject.
keyed_fold can also be provided with one generic lifetime persistence argument, either
'tick or 'static, to specify how data persists. With 'tick, values will only be collected
within the same tick. With 'static, values will be remembered across ticks and will be
aggregated with pairs arriving in later ticks. When not explicitly specified persistence
defaults to 'static.
keyed_fold can also be provided with two type arguments, the key type K and aggregated
output value type V2. This is required when using 'static persistence if the compiler
cannot infer the types.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_iter([("toy", 1), ("toy", 2), ("shoe", 11), ("shoe", 35), ("haberdashery", 7)]) -> keyed_fold(|| 0, |old: &mut u32, val: u32| *old += val) -> for_each(|(k, v)| println!("Total for group {} is {}", k, v)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
Example using 'tick persistence:
#![allow(unused)] fn main() { let (input_send, input_recv) = hydroflow::util::unbounded_channel::<(&str, &str)>(); let mut flow = hydroflow::hydroflow_syntax! { source_stream(input_recv) -> keyed_fold::<'tick, &str, String>(String::new, |old: &mut _, val| { *old += val; *old += ", "; }) -> for_each(|(k, v)| println!("({:?}, {:?})", k, v)); }; input_send.send(("hello", "oakland")).unwrap(); input_send.send(("hello", "berkeley")).unwrap(); input_send.send(("hello", "san francisco")).unwrap(); flow.run_available(); // ("hello", "oakland, berkeley, san francisco, ") input_send.send(("hello", "palo alto")).unwrap(); flow.run_available(); // ("hello", "palo alto, ") }
keyed_reduce
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> keyed_reduce(A) -> | exactly 1 | Blocking |
1 input stream of type
(K, V), 1 output stream of type(K, V). The output will have one tuple for each distinctK, with an accumulated (reduced) value of typeV.
If you need the accumulated value to have a different type, use keyed_fold.
Arguments: one Rust closures. The closure takes two arguments: an
&mut'accumulator', and an element. Accumulator should be updated based on the element.
A special case of fold, in the spirit of SQL's GROUP BY and aggregation constructs. The input
is partitioned into groups by the first field, and for each group the values in the second
field are accumulated via the closures in the arguments.
Note: The closures have access to the
contextobject.
keyed_reduce can also be provided with one generic lifetime persistence argument, either
'tick or 'static, to specify how data persists. With 'tick, values will only be collected
within the same tick. With 'static, values will be remembered across ticks and will be
aggregated with pairs arriving in later ticks. When not explicitly specified persistence
defaults to 'static.
keyed_reduce can also be provided with two type arguments, the key and value type. This is
required when using 'static persistence if the compiler cannot infer the types.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_iter([("toy", 1), ("toy", 2), ("shoe", 11), ("shoe", 35), ("haberdashery", 7)]) -> keyed_reduce(|old: &mut u32, val: u32| *old += val) -> for_each(|(k, v)| println!("Total for group {} is {}", k, v)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
Example using 'tick persistence:
#![allow(unused)] fn main() { let (input_send, input_recv) = hydroflow::util::unbounded_channel::<(&str, &str)>(); let mut flow = hydroflow::hydroflow_syntax! { source_stream(input_recv) -> keyed_reduce::<'tick, &str>(|old: &mut _, val| *old = std::cmp::max(*old, val)) -> for_each(|(k, v)| println!("({:?}, {:?})", k, v)); }; input_send.send(("hello", "oakland")).unwrap(); input_send.send(("hello", "berkeley")).unwrap(); input_send.send(("hello", "san francisco")).unwrap(); flow.run_available(); // ("hello", "oakland, berkeley, san francisco, ") input_send.send(("hello", "palo alto")).unwrap(); flow.run_available(); // ("hello", "palo alto, ") }
lattice_batch
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> lattice_batch(A) -> | exactly 1 | Streaming |
1 input stream, 1 output stream
Arguments: The one and only argument is the receive end of a tokio channel that signals when to release the batch downstream.
Given a Stream
created in Rust code, lattice_batch
is passed the receive end of the channel and when receiving any element
will pass through all received inputs to the output unchanged.
#![allow(unused)] fn main() { let (tx, rx) = hydroflow::util::unbounded_channel::<()>(); // Will print 0, 1, 2, 3, 4 each on a new line just once. let mut df = hydroflow::hydroflow_syntax! { repeat_iter(0..5) -> map(|x| hydroflow::lattices::Max::new(x)) -> lattice_batch::<hydroflow::lattices::Max<usize>>(rx) -> for_each(|x| { println!("{x:?}"); }); }; tx.send(()).unwrap(); df.run_available(); }
lattice_join
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 2 | -> [<input_port>]lattice_join() -> | exactly 1 | Streaming |
Input port names:
0(streaming),1(streaming)
2 input streams of type <(K, V1)> and <(K, V2)>, 1 output stream of type <(K, (V1, V2))>
Performs a group-by with lattice-merge aggregate function on LHS and RHS inputs and then forms the equijoin of the tuples in the input streams by their first (key) attribute. Note that the result nests the 2nd input field (values) into a tuple in the 2nd output field.
You must specify the LHS and RHS lattice types, they cannot be inferred.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print `(key, (2, 1))` my_join = lattice_join::<hydroflow::lattices::Max<usize>, hydroflow::lattices::Max<usize>>(); source_iter(vec![("key", hydroflow::lattices::Max::new(0)), ("key", hydroflow::lattices::Max::new(2))]) -> [0]my_join; source_iter(vec![("key", hydroflow::lattices::Max::new(1))]) -> [1]my_join; my_join -> for_each(|(k, (v1, v2))| println!("({}, ({:?}, {:?}))", k, v1, v2)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
lattice_join can also be provided with one or two generic lifetime persistence arguments, either
'tick or 'static, to specify how join data persists. With 'tick, pairs will only be
joined with corresponding pairs within the same tick. With 'static, pairs will be remembered
across ticks and will be joined with pairs arriving in later ticks. When not explicitly
specified persistence defaults to `static.
When two persistence arguments are supplied the first maps to port 0 and the second maps to
port 1.
When a single persistence argument is supplied, it is applied to both input ports.
When no persistence arguments are applied it defaults to 'static for both.
The syntax is as follows:
lattice_join::<MaxRepr<usize>, MaxRepr<usize>>(); // Or
lattice_join::<'static, MaxRepr<usize>, MaxRepr<usize>>();
lattice_join::<'tick, MaxRepr<usize>, MaxRepr<usize>>();
lattice_join::<'static, 'tick, MaxRepr<usize>, MaxRepr<usize>>();
lattice_join::<'tick, 'static, MaxRepr<usize>, MaxRepr<usize>>();
// etc.
Examples
#![allow(unused)] fn main() { use hydroflow::lattices::Max; let (input_send, input_recv) = hydroflow::util::unbounded_channel::<(usize, Max<usize>)>(); let (out_tx, mut out_rx) = hydroflow::util::unbounded_channel::<(usize, (Max<usize>, Max<usize>))>(); let mut df = hydroflow::hydroflow_syntax! { my_join = lattice_join::<'tick, Max<usize>, Max<usize>>(); source_iter([(7, Max::new(2)), (7, Max::new(1))]) -> [0]my_join; source_stream(input_recv) -> [1]my_join; my_join -> for_each(|v| out_tx.send(v).unwrap()); }; input_send.send((7, Max::new(5))).unwrap(); df.run_tick(); let out: Vec<_> = hydroflow::util::collect_ready(&mut out_rx); assert_eq!(out, vec![(7, (Max::new(2), Max::new(5)))]); }
lattice_merge
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> lattice_merge() -> | exactly 1 | Blocking |
1 input stream, 1 output stream
Generic parameters: A
LatticeReprtype.
A specialized operator for merging lattices together into a accumulated value. Like fold()
but specialized for lattice types. lattice_merge::<MyLattice>() is equivalent to fold(Default::default, hydroflow::lattices::Merge::merge_owned).
lattice_merge can also be provided with one generic lifetime persistence argument, either
'tick or 'static, to specify how data persists. With 'tick, values will only be collected
within the same tick. With 'static, values will be remembered across ticks and will be
aggregated with pairs arriving in later ticks. When not explicitly specified persistence
defaults to 'static.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_iter([1,2,3,4,5]) -> map(hydroflow::lattices::Max::new) -> lattice_merge::<'static, hydroflow::lattices::Max<usize>>() -> for_each(|x: hydroflow::lattices::Max<usize>| println!("Least upper bound: {}", x.0)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
map
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> map(A) -> | exactly 1 | Streaming |
1 input stream, 1 output stream
Arguments: A Rust closure For each item passed in, apply the closure to generate an item to emit.
If you do not want to modify the item stream and instead only want to view
each item use the inspect operator instead.
Note: The closure has access to the
contextobject.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_iter(vec!["hello", "world"]) -> map(|x| x.to_uppercase()) -> for_each(|x| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
merge
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| at least 2 | -> [<input_port>]merge() -> | exactly 1 | Streaming |
n input streams of the same type, 1 output stream of the same type
Merges an arbitrary number of input streams into a single stream. Each input sequence is a subsequence of the output, but no guarantee is given on how the inputs are interleaved.
Since merge has multiple input streams, it needs to be assigned to
a variable to reference its multiple input ports across statements.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_iter(vec!["hello", "world"]) -> my_merge; source_iter(vec!["stay", "gold"]) -> my_merge; source_iter(vec!["don\'t", "give", "up"]) -> my_merge; my_merge = merge() -> map(|x| x.to_uppercase()) -> for_each(|x| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
next_stratum
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> next_stratum() -> | exactly 1 | Blocking |
Delays all elements which pass through to the next stratum (in the same tick).
next_tick
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> next_tick() -> | exactly 1 | Blocking |
Delays all elements which pass through to the next tick. In short, execution of a hydroflow graph runs as a sequence of distinct "ticks". Non-monotonic operators compute their output in terms of each tick so execution doesn't have to block, and it is up to the user to coordinate data between tick executions to achieve the desired result.
An tick may be divided into multiple strata, see the next_stratum()
operator.
In the example below next_tick() is used alongside difference() to
ignore any items in the current tick that already appeared in the previous
tick.
#![allow(unused)] fn main() { // Outputs 1 2 3 4 5 6 (on separate lines). let (input_send, input_recv) = hydroflow::util::unbounded_channel::<usize>(); let mut flow = hydroflow::hydroflow_syntax! { inp = source_stream(input_recv) -> tee(); diff = difference() -> for_each(|x| println!("{}", x)); inp -> [pos]diff; inp -> next_tick() -> [neg]diff; }; for x in [1, 2, 3, 4] { input_send.send(x).unwrap(); } flow.run_tick(); for x in [3, 4, 5, 6] { input_send.send(x).unwrap(); } flow.run_tick(); }
null
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| at least 0 and at most 1 | null() | at least 0 and at most 1 | Streaming |
unbounded number of input streams of any type, unbounded number of output streams of any type.
As a source, generates nothing. As a sink, absorbs anything with no effect.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print `1, 2, 3, 4, 5, 6, a, b, c` across 9 lines null() -> for_each(|_: ()| panic!()); source_iter([1,2,3]) -> map(|i| println!("{}", i)) -> null(); null_src = null(); null_sink = null(); null_src[0] -> for_each(|_: ()| panic!()); // note: use `for_each()` (or `inspect()`) instead of this: source_iter([4,5,6]) -> map(|i| println!("{}", i)) -> [0]null_sink; }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
persist
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> persist() -> | exactly 1 | Streaming |
Stores each item as it passes through, and replays all item every tick.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // Normally `source_iter(...)` only emits once, but with `persist()` will replay the `"hello"` // on every tick. This is equivalent to `repeat_iter(["hello"])`. source_iter(["hello"]) -> persist() -> for_each(|item| println!("{}: {}", context.current_tick(), item)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
persist() can be used to introduce statefulness into stateless pipelines. For example this
join only stores data for single 'tick. The persist() operator introduces statefulness
across ticks. This can be useful for optimization transformations within the hydroflow
compiler.
#![allow(unused)] fn main() { let (input_send, input_recv) = hydroflow::util::unbounded_channel::<(&str, &str)>(); let mut flow = hydroflow::hydroflow_syntax! { repeat_iter([("hello", "world")]) -> [0]my_join; source_stream(input_recv) -> persist() -> [1]my_join; my_join = join::<'tick>() -> for_each(|(k, (v1, v2))| println!("({}, ({}, {}))", k, v1, v2)); }; input_send.send(("hello", "oakland")).unwrap(); flow.run_tick(); input_send.send(("hello", "san francisco")).unwrap(); flow.run_tick(); // (hello, (world, oakland)) // (hello, (world, oakland)) // (hello, (world, san francisco)) }
reduce
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> reduce(A) -> | exactly 1 | Blocking |
1 input stream, 1 output stream
Arguments: a closure which itself takes two arguments: an ‘accumulator’, and an element. The closure returns the value that the accumulator should have for the next iteration.
Akin to Rust's built-in reduce operator. Folds every element into an accumulator by applying a closure, returning the final result.
Note: The closure has access to the
contextobject.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print 120 (i.e., 1*2*3*4*5) source_iter([1,2,3,4,5]) -> reduce(|mut accum, elem| { accum *= elem; accum }) -> for_each(|e| println!("{}", e)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
repeat_fn
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 0 | repeat_fn(A, B) -> | exactly 1 | Streaming |
0 input streams, 1 output stream
Arguments: A batch size per tick, and a zero argument closure to produce each item in the stream. Similar to
repeat_iter, but generates the items by calling the supplied closure instead of cloning them from an input iter
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { repeat_fn(10, || 7) -> for_each(|x| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
repeat_iter
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 0 | repeat_iter(A) -> | exactly 1 | Streaming |
0 input streams, 1 output stream
Arguments: An iterable Rust object. Similar to
source_iter, but delivers all elements from the iterable object on every tick (wheresource_iteronly delivers on the first tick).
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { repeat_iter(vec!["Hello", "World"]) -> for_each(|x| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
repeat_iter_external
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 0 | repeat_iter_external(A) -> | exactly 1 | Streaming |
Same as repeat_iter but treats the iter as external, meaning this operator
will trigger the start of new ticks in order to repeat, causing spinning-like behavior.
sort
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> sort() -> | exactly 1 | Blocking |
Takes a stream as input and produces a sorted version of the stream as output.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print 1, 2, 3 (in order) source_iter(vec![2, 3, 1]) -> sort() -> for_each(|x| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
sort can also be provided with one generic lifetime persistence argument, either
'tick or 'static, to specify how data persists. The default is 'tick. With 'tick only
the values will only be collected within a single tick will be sorted and emitted. With
'static, values will be remembered across ticks and will be repeatedly emitted each tick (in
order).
#![allow(unused)] fn main() { let (input_send, input_recv) = hydroflow::util::unbounded_channel::<usize>(); let mut flow = hydroflow::hydroflow_syntax! { source_stream(input_recv) -> sort::<'static>() -> for_each(|n| println!("{}", n)); }; input_send.send(6).unwrap(); input_send.send(3).unwrap(); input_send.send(4).unwrap(); flow.run_available(); // 3, 4, 6 input_send.send(1).unwrap(); input_send.send(7).unwrap(); flow.run_available(); // 1, 3, 4, 6, 7 }
sort_by
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> sort_by(A) -> | exactly 1 | Blocking |
Takes a stream as input and produces a version of the stream as output sorted according to the key extracted by the closure.
Note: The closure has access to the
contextobject.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print (1, 'z'), (2, 'y'), (3, 'x') (in order) source_iter(vec![(2, 'y'), (3, 'x'), (1, 'z')]) -> sort_by(|(k, _v)| k) -> for_each(|x| println!("{:?}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
source_file
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 0 | source_file(A) -> | exactly 1 | Streaming |
0 input streams, 1 output stream
Reads the referenced file one line at a time. The line will NOT include the line ending.
Will panic if the file could not be read, or if the file contains bytes that are not valid UTF-8.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_file("Cargo.toml") -> for_each(|line| println!("{}", line)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
source_interval
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 0 | source_interval(A) -> | exactly 1 | Streaming |
0 input streams, 1 output stream
Arguments: A
Durationfor this interval.
Emits Tokio time Instants on a
repeated interval. The first tick completes imediately. Missed ticks will be scheduled as soon
as possible, and the Instant will be the missed time, not the late time.
Note that this requires the hydroflow instance be run within a Tokio Runtime.
The easiest way to do this is with a #[tokio::main]
annotation on async fn main() { ... }.
use std::time::Duration; use hydroflow::hydroflow_syntax; #[tokio::main] async fn main() { let mut hf = hydroflow_syntax! { source_interval(Duration::from_secs(1)) -> for_each(|time| println!("This runs every second: {:?}", time)); }; // Will print 4 times (fencepost counting). tokio::time::timeout(Duration::from_secs_f32(3.5), hf.run_async()) .await .expect_err("Expected time out"); // Example output: // This runs every second: Instant { t: 27471.704813s } // This runs every second: Instant { t: 27472.704813s } // This runs every second: Instant { t: 27473.704813s } // This runs every second: Instant { t: 27474.704813s } }
source_iter
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 0 | source_iter(A) -> | exactly 1 | Streaming |
0 input streams, 1 output stream
Arguments: An iterable Rust object. Takes the iterable object and delivers its elements downstream one by one.
Note that all elements are emitted during the first tick.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_iter(vec!["Hello", "World"]) -> for_each(|x| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
source_json
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 0 | source_json(A) -> | exactly 1 | Streaming |
0 input streams, 1 output stream
Arguments: An
AsRef<Path>for a file to read as json. This will emit the parsed value one time.
source_json may take one generic type argument, the type of the value to be parsed, which must implement Deserialize.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { source_json("example.json") -> for_each(|json: hydroflow::serde_json::Value| println!("{:#?}", json)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
source_stdin
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 0 | source_stdin() -> | exactly 1 | Streaming |
0 input streams, 1 output stream
Arguments: port number
source_stdin receives a Stream of lines from stdin
and emits each of the elements it receives downstream.
#![allow(unused)] fn main() { let mut flow = hydroflow::hydroflow_syntax! { source_stdin() -> map(|x| x.unwrap().to_uppercase()) -> for_each(|x| println!("{}", x)); }; flow.run_async(); }
source_stream
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 0 | source_stream(A) -> | exactly 1 | Streaming |
0 input streams, 1 output stream
Arguments: The receive end of a tokio channel
Given a Stream
created in Rust code, source_stream
is passed the receive endpoint of the channel and emits each of the
elements it receives downstream.
#![allow(unused)] fn main() { let (input_send, input_recv) = hydroflow::util::unbounded_channel::<&str>(); let mut flow = hydroflow::hydroflow_syntax! { source_stream(input_recv) -> map(|x| x.to_uppercase()) -> for_each(|x| println!("{}", x)); }; input_send.send("Hello").unwrap(); input_send.send("World").unwrap(); flow.run_available(); }
source_stream_serde
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 0 | source_stream_serde(A) -> | exactly 1 | Streaming |
0 input streams, 1 output stream
Arguments:
Stream
Given a Stream
of (serialized payload, addr) pairs, deserializes the payload and emits each of the
elements it receives downstream.
#![allow(unused)] fn main() { async fn serde_in() { let addr = hydroflow::util::ipv4_resolve("localhost:9000".into()).unwrap(); let (outbound, inbound, _) = hydroflow::util::bind_udp_bytes(addr).await; let mut flow = hydroflow::hydroflow_syntax! { source_stream_serde(inbound) -> map(Result::unwrap) -> map(|(x, a): (String, std::net::SocketAddr)| x.to_uppercase()) -> for_each(|x| println!("{}", x)); }; flow.run_available(); } }
tee
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> tee()[<output_port>] -> | at least 2 | Streaming |
1 input stream, n output streams
Takes the input stream and delivers a copy of each item to each output.
Note: Downstream operators may need explicit type annotations.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { my_tee = source_iter(vec!["Hello", "World"]) -> tee(); my_tee -> map(|x: &str| x.to_uppercase()) -> for_each(|x| println!("{}", x)); my_tee -> map(|x: &str| x.to_lowercase()) -> for_each(|x| println!("{}", x)); my_tee -> for_each(|x: &str| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
unique
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> unique() -> | exactly 1 | Streaming |
Takes one stream as input and filters out any duplicate occurrences. The output contains all unique values from the input.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { // should print 1, 2, 3 (in any order) source_iter(vec![1, 1, 2, 3, 2, 1, 3]) -> unique() -> for_each(|x| println!("{}", x)); }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
unique can also be provided with one generic lifetime persistence argument, either
'tick or 'static, to specify how data persists. The default is 'static.
With 'tick, uniqueness is only considered within the current tick, so across multiple ticks
duplicate values may be emitted.
With 'static, values will be remembered across ticks and no duplicates will ever be emitted.
#![allow(unused)] fn main() { let (input_send, input_recv) = hydroflow::util::unbounded_channel::<usize>(); let mut flow = hydroflow::hydroflow_syntax! { source_stream(input_recv) -> unique::<'tick>() -> for_each(|n| println!("{}", n)); }; input_send.send(3).unwrap(); input_send.send(3).unwrap(); input_send.send(4).unwrap(); input_send.send(3).unwrap(); flow.run_available(); // 3, 4 input_send.send(3).unwrap(); input_send.send(5).unwrap(); flow.run_available(); // 3, 5 // Note: 3 is emitted again. }
unzip
| Inputs | Syntax | Outputs | Flow |
|---|---|---|---|
| exactly 1 | -> unzip()[<output_port>] -> | exactly 2 | Streaming |
Output port names:
0,1
1 input stream of pair tuples
(A, B), 2 output streams
Takes the input stream of pairs and unzips each one, delivers each item to its corresponding side.
#![allow(unused)] fn main() { #[allow(unused_imports)] use hydroflow::{var_args, var_expr}; #[allow(unused_imports)] use hydroflow::pusherator::Pusherator; let __rt = hydroflow::tokio::runtime::Builder::new_current_thread().enable_all().build().unwrap(); __rt.block_on(async { let mut __hf = hydroflow::hydroflow_syntax! { my_unzip = source_iter(vec![("Hello", "Foo"), ("World", "Bar")]) -> unzip(); my_unzip[0] -> for_each(|x| println!("0: {}", x)); // Hello World my_unzip[1] -> for_each(|x| println!("1: {}", x)); // Foo Bar }; for _ in 0..100 { hydroflow::tokio::task::yield_now().await; if !__hf.run_tick() { // No work done. break; } } }) }
State and Lifetimes
The Hydro Ecosystem
The Hydro Project is an evolving stack of libraries and languages for distributed programming. A rough picture of the envisioned Hydro stack is below:
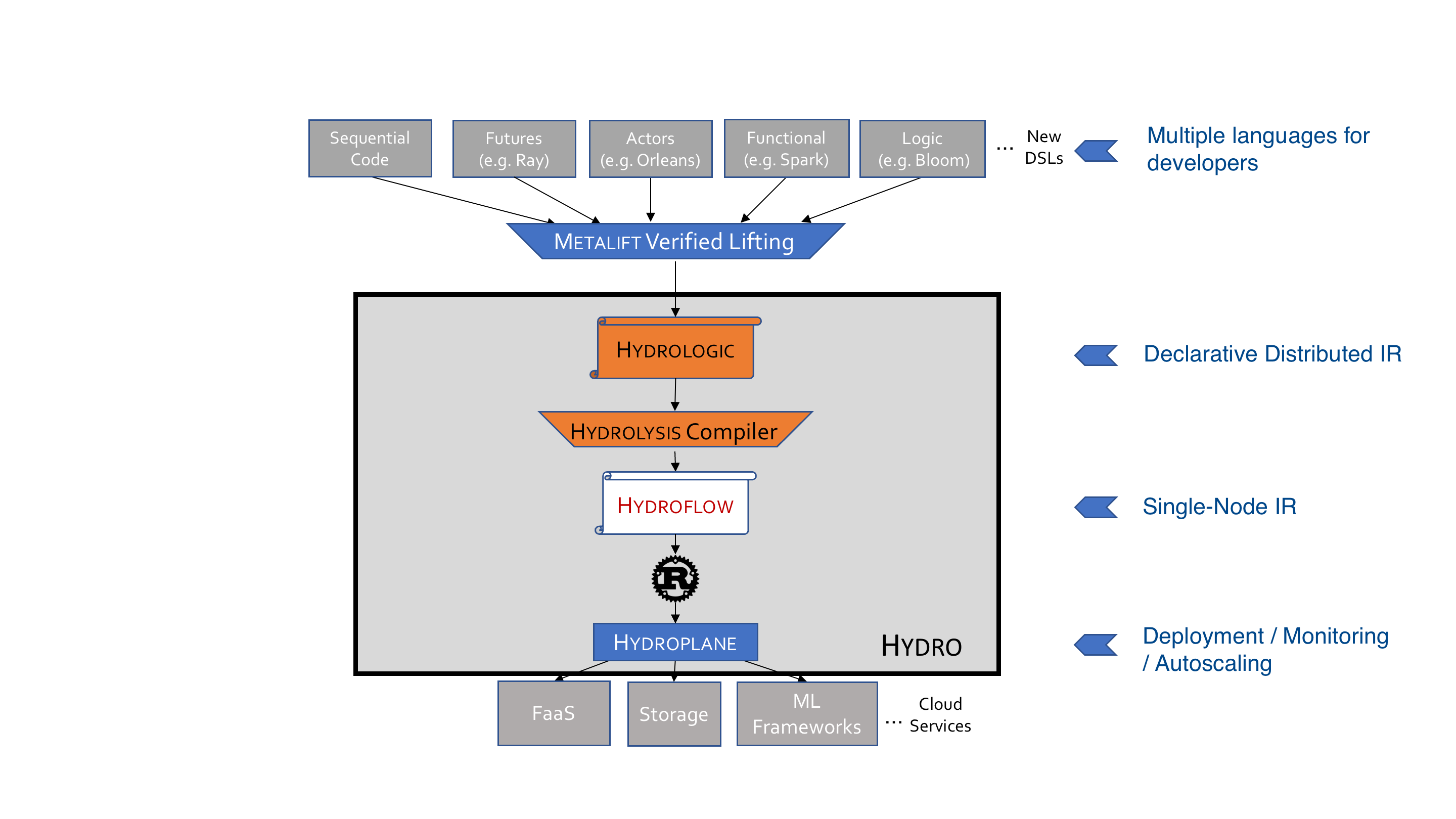
The core of the Hydro stack is shown in in the grey box; components that have not been implemented are in orange.
Working up from the bottom:
-
Hydroplane is a service for launching and monitoring Hydroflow transducers. It works both on local developer machines with Docker, and in cloud services like AWS EKS. Over time we expect to add autoscaling features to Hydroplane, to allow users to configure the cluster to grow and shrink based on the monitored behavior and a pluggable policy.
-
Hydroflow is the subject of this book; a library for defining individual transducers in a distributed system. It uses the Rust compiler to generate binaries for deployment.
-
Hydrolysis is a compiler we envision translating from Hydrologic to Hydroflow.
-
Hydrologic is a high-level domain-specific language that we envision for distributed programming. Unlike Hydroflow, we expect Hydrologic to abstract away many notions of distributed computing. In particular, Hydrologic will be insensitive to the specific deployment of the code—the partitioning of functionality and data across transducers, the number of replicas of each transducer, etc. Instead, programmers will provide specifications for desired properties like the number of failures to tolerate, the consistency desired at a given endpoint, the latency of a given endpoint, etc. The Hydrolysis compiler will then generate Hydroflow transducers that can be deployed by Hydroplane to meet those specifications.
-
Metalift is a framework for "lifting" code from one language to a (typically higher-level) language. We envision that Metalift will be used to translate from one of many distributed programming models/languages into our common Internal Representation, Hydrologic.
The Hydro stack is inspired by previous language stacks including LLVM and Halide, which similarly expose multiple human-programmable Internal Representation langauges.
An early paper on the Hydro vision appeared in CIDR 2021, under the title New Directions in Cloud Programming.
Concepts
Hydroflow is different from other distributed systems infrastructure, so you probably have questions, like: What is Hydroflow? How does it work? What is special about it, and what are the key concepts to understand?
This chapter covers those basic questions. We start simple describing Hydroflow, and build up to an understanding of what makes Hydroflow uniquely powerful.
But in case you want a preview of the Hydroflow goodies, here are the main themes:
- Distributed Correctness: Hydroflow's type system can prevent distributed system bugs at compile time. (One example: will your code produce the same results if you deploy on a single machine or replicate on a distributed cluster of machines?)
- Local Efficiency: Hydroflow compiles your dataflow programs into efficient, low-latency, single-threaded executables.
Taken together, Hydroflow provides a high-efficiency substrate on which to build powerful languages for distributed computing.
Hydroflow's type system checks are not yet implemented, but they are coming soon!
Hydroflow: A Runtime Library and a DSL in Rust
Setting fanfare aside, what is Hydroflow?
Hydroflow is a library that can be used in any Rust program. It includes two main components:
- A runtime library that executes low-latency, reactive dataflow programs written in Rust. (The core API.)
- A domain-specific language (DSL) for specifying dataflow programs. (The Hydroflow surface syntax.)
Hydroflow's surface syntax must be embedded in a Rust program; the Rust compiler takes that Hydroflow syntax and compiles it into an efficient binary executable.
We call a running Hydroflow binary a transducer.
In typical usage, a developer writes a transducer as a single-threaded Rust program that is mostly composed of Hydroflow surface syntax. Each transducer is typically responsible for a single "node" (a machine, or a core) in a distributed system composed of many such transducers, which send and receive flows of data to each other.
Hydroflow itself does not generate distributed code. It is a library for specifying the transducers (individual nodes) that participate in a distributed system.
In the Hydro Project, higher-level languages are being built on top of Hydroflow to generate distributed code in the form of multiple transducers. Meanwhile, you can use Hydroflow to write your own distributed code, by writing individual transducers that work together, and deploying them manually or with a tool like Hydroplane. See the Hydro Ecosystem for more on this.
So how might a human write distributed systems with Hydroflow?
As an illustration of how you can work at the Hydroflow layer, consider the
Chat Server example. If you run that binary
with the command-line argument --role server it will start a single transducer that is responsible for a chat server: receiving
membership requests and messages from clients, and forwarding messages from individual clients to all other clients.
If you run that binary with the argument --role client it will start a transducer that is responsible for a chat client, which
forwards chat messages from stdin to the server, and prints out messages sent by the server. As a distributed system, the chat
service would typically consist of many client transducers and a single server transducer.
Note that this is an example of an extremely simple distributed system in a "star" or "hub-and spokes" topology: the multiple client transducers are completely independent of each other, and each talks only with the central server transducer.
%%{init: {'theme':'neutral'}}%%
graph TD;
Client1---S((Server));
Client2---S;
Client3---S;
S---Client4;
S---Client5;
S---Client6;
If we wanted something more interesting, we could consider deploying a cluster of multiple server transducers, say for fault tolerance or geo-distribution, perhaps like this:
%%{init: {'theme':'neutral'}}%%
graph LR;
subgraph servers[Server Cluster]
S1((Server1))---S2((Server2))---S3((Server3))---S1;
end
Client1---S1;
Client2---S1;
Client3---S2;
S2---Client4;
S3---Client5;
S3---Client6;
We'd need to change the server code to get servers sharing their state in a correct and reliable manner. But that's a topic for another section TODO; for now, let's stay focused on the basics.
The Life and Times of a Hydroflow Transducer
Time is a fundamental concept in many distributed systems. Hydroflow's model of time is very simple, but also powerful enough to serve as a building block for more complex models of time.
Like most reactive services, we can envision a Hydroflow transducer running as an unbounded loop that is managed
by the runtime library. Each iteration of the transducer's loop is called a tick. Associated with the transducer is
a clock value (accessible via the .current_tick() method), which tells you how many ticks were executed
by this transducer prior to the current tick. Each transducer produces totally ordered, sequentially increasing clock values,
which you can think of as the "local logical time" at the transducer.
The transducer's main loop works as follows:
- Given events and messages buffered from the operating system, ingest a batch of data items and deliver them to the appropriate
source_xxxoperators in the Hydroflow spec. - Run the Hydroflow spec. If the spec has cycles, continue executing it until it reaches a "fixpoint" on the current batch; i.e. it no longer produces any new data anywhere in the flow. Along the way, any data that appears in an outbound channel is streamed to the appropriate destination.
- Once the spec reaches fixpoint and messages have all been sent, advance the local clock and then start the next tick.
The transducer's main loop is shown in the following diagram:
%%{init: {'theme':'neutral'}}%%
flowchart LR
subgraph external[External]
network>"messages\n& events"\nfa:fa-telegram]-->buffer[[buffer]]
end
subgraph transducer[Transducer Loop]
buffer-->ingest>ingest a batch\nof data]-->loop(((run Hydroflow\nspec to fixpoint\nfa:fa-cog)))-->stream[stream out\nmsgs & events\nfa:fa-telegram]-->clock((advance\nclock\nfa:fa-clock-o))-- new tick! -->ingest
end
style stream fill:#0fa,stroke:#aaa,stroke-width:2px,stroke-dasharray: 5 5
style loop fill:#0fa
style clock fill:#f00
style ingest fill:#f00
linkStyle 5 stroke:red,stroke-width:4px,color:red;
In sum, an individual transducer advances sequentially through logical time; in each tick of its clock it ingests a batch of data from its inbound channels, executes the Hydroflow spec, and sends any outbound data to its outbound channels.
Streaming, Blocking and Stratification
Many Hydroflow operators (e.g. map, filter and join) work in a streaming fashion. Streaming operators process data as it arrives, generating outputs in the midst of processing inputs. If you restrict yourself to operators that work in this streaming fashion, then your transducer may start sending data across the network mid-tick, even while it is still consuming the data in the input batch.
But some operators are blocking, and must wait for all their input data to arrive before they can produce any output data. For example, a sort operator must wait for all its input data to arrive before it can produce a single output value. After all, the lowest value may be the last to arrive!
Examples of Blocking Operators
The discussion above should raise questions in your mind. What do we mean by "all the input data" in a long-running service? We don't want to wait until the end of time—this is one reason we break time up into discrete "ticks" at each transducer. So when we say that a blocking operator waits for "all the input data", we mean "all the input data in the current tick".
Consider the simple statement below, which receives data from a network source each tick, sorts that tick's worth of data, and prints it to stdout:
source_stream(inbound) -> sort() -> for_each(|x| println!("{:?}", x));The runtime determines arbitrarily what batch of data is taken from the channel and fed into the source_stream_serde operator for this tick. The sort operator will need to know that the source_stream_serde operator has no more data to send this tick, so that it can sort the data that got buffered and then send the sorted data to the for_each operator, which prints it to stdout. To do this, the runtime provides a mechanism for the source_stream_serde operator to buffer its output and notify the sort operator that it has no more data to send. This is called a handoff.
You can see the mermaid graph for the statement above just below this paragraph. Notice the two outer rectangles and the handoff between them. Each rectangle is a subflow that is assigned a stratum number. ("Stratum" is latin for "layer"; the plural of "stratum" is "strata".)
%%{init: {'theme': 'base', 'themeVariables': {'clusterBkg':'#ddd'}}}%%
flowchart LR
classDef pullClass fill:#02f,color:#fff,stroke:#000
classDef pushClass fill:#ff0,stroke:#000
linkStyle default stroke:#aaa,stroke-width:4px,color:red,font-size:1.5em;
subgraph "sg_1v1 stratum 0"
1v1[\"(1v1) <tt>source_stream(edges_recv)</tt>"/]:::pullClass
end
subgraph "sg_2v1 stratum 1"
2v1[/"(2v1) <tt>sort()</tt>"\]:::pushClass
3v1[/"(3v1) <tt>for_each(| x | println! ("{:?}", x))</tt>"\]:::pushClass
2v1--->3v1
end
1v1--->4v1
4v1["(4v1) <tt>handoff</tt>"]:::otherClass
4v1===o2v1
At compile time, the Hydroflow spec is stratified: partitioned into subflows, where each subflow is assigned a stratum number. Subsequently at runtime, each tick executes the strata one-by-one in ascending order of stratum number. In the example above, the source_stream operator is in stratum 0, and the sort and for_each operators are in stratum 1. The runtime executes the source_stream operator first, buffering output in the Handoff. The sort operator will not receive any data until the source_stream operator has finished executing. When stratum 0 is complete, the subflow in stratum 1 is scheduled and executes the sort and for_each operators to complete the tick.
Let's look back at the difference operator as used in the Graph Unreachability example.
flowchart TD
classDef pullClass fill:#02f,color:#fff,stroke:#000
classDef pushClass fill:#ff0,stroke:#000
linkStyle default stroke:#aaa,stroke-width:4px,color:red,font-size:1.5em;
subgraph "sg_4v1 stratum 1"
11v1[\"(11v1) <tt>difference()</tt>"/]:::pullClass
14v1[/"(14v1) <tt>for_each(| v | println! ("unreached_vertices vertex: {}", v))</tt>"\]:::pushClass
11v1--->14v1
end
17v1["(17v1) <tt>handoff</tt>"]:::otherClass
17v1--pos--->11v1
18v1["(18v1) <tt>handoff</tt>"]:::otherClass
18v1==neg===o11v1
The difference operators is one with inputs of two different types. It is supposed to output all the items from its pos input that do not appear in its neg input. To achieve that, the neg input must be blocking, but the pos input can stream. Blocking on the neg input ensures that if the operator streams an output from the pos input, it will never need to retract that output.
Given these examples, we can refine our diagram of the Hydroflow transducer loop to account for stratified execution within each tick:
%%{init: {'theme':'neutral'}}%%
flowchart LR
subgraph external[External]
network>"messages\n& events"\nfa:fa-telegram]-->buffer[[buffer]]
end
subgraph transducer[Transducer Loop]
buffer-->ingest>"ingest a batch\nof data"]-->loop((("for each stratum in\n[0..max(strata)]\nrun stratum to fixpoint\nfa:fa-cog")))-->stream[stream out\nmsgs & events\nfa:fa-telegram]-->clock((advance\nclock\nfa:fa-clock-o))-- new tick! -->ingest
end
style stream fill:#0fa,stroke:#aaa,stroke-width:2px,stroke-dasharray: 5 5
style loop fill:#0fa
style clock fill:#f00
style ingest fill:#f00
linkStyle 5 stroke:red,stroke-width:4px,color:red;
Technical Details
The concept of stratification is taken directly from stratified negation in the Datalog language. Hydroflow identifies a stratum boundary at any blocking input to an operator, where classical Datalog only stratifies its negation operator.
The Hydroflow compiler performs stratification via static analysis of the Hydroflow spec. The analysis is based on the following rules:
- A Handoff is interposed in front of any blocking input to an operator (as documented in the operator definitions.
- The flow is partitioned at the Handoffs into subflows called "strata".
- The resulting graph of strata and Handoffs is tested to ensure that it's acyclic. (Cycles through blocking operators are forbidden as they not have well-defined behavior—note that the blocking operators in a cycle would deadlock waiting for each other.)
Given the acyclicity test, any legal Hydroflow program consists of a directed acyclic graph (DAG) of strata and handoffs. The strata are numbered in ascending order by assigning stratum number 0 to the "leaves" of the DAG (strata with no upstream operators), and then ensuring that each stratum is assigned a number that is one larger than any of its upstream strata.
As a Hydroflow operator executes, it is running on a particular transducer, in a particular tick, in a particular stratum.
Determining whether an operator should block: Monotonicity
Why are some inputs to operators streaming, and others blocking? Intuitively, the blocking operators must hold off on emitting outputs early because they may receive another input that would change their output. For example, a difference operator on integers cannot emit the number 4 from its pos input if it may subsequently receive a 4 within the same tick on the neg input. More generally, it cannot output anything until it has received all the neg input data.
By contrast, streaming operators like filter have the property that they can always emit an output, regardless of what other data they will receive later in the tick.
Mathematically, we can think of a dataflow operator as a function f(in) → out from one batch of data to another. We call a function monotone if its output is a growing function of its input. That is, f is classified as a monotone function if f(B) ⊆ f(C) whenever B ⊆ C.
By contrast, consider the output of a blocking operator like difference. The output of difference is a function of both its inputs, but it is non-monotone with respect to its neg input. That is, it is not the case that (A — B) ⊆ (A — C) whenever B ⊆ C.
Hydroflow is designed to use the monotonicity property to determine whether an operator should block. If an operator is monotone with respect to an input, that input is streaming. If an operator is non-monotone, it is blocking.
Monotonicity turns out to be particularly important for distributed systems. In particular, if all your transducers are fully monotone across ticks, then they can run in parallel without any coordination—they will always stream correct prefixes of the final outputs, and eventually will deliver the complete output. This is the positive direction of the CALM Theorem.
In future versions of Hydroflow, the type system will represent monotonicity explicitly and reason about it automatically.
Distributed Time
Hydroflow does not embed a particular notion of distributed time, but instead provides primitives for you to implement one of many possible distributed time models. If you're a distributed systems aficionado, you might be interested to read this chapter to learn about how Hydroflow's time model compares to classical distributed time models.
Lamport Time
Lamport's paper on Time, Clocks, and the Ordering of Events in a Distributed System provides a classical definition of time in a distributed system. In that paper, each single-threaded process has a sequential clock (a so-called Lamport Clock). The clock in a process advances by one unit of time for each event that the process observes. Between events, the clock is frozen and the process does local computation.
In addition, to maintain Lamport Clocks, each process stamps its outbound messages with the current clock value, and begins each "tick" by advancing its local clock to the larger of
- its current clock value and
- the largest clock value of any message it received.
The way that Lamport clocks jump ahead provides a desirable property: the timestamps provide a reasonable notion of what events happen-before other events in a distributed system.
Lamport timestamps track not only the order of events on a single node, they also ensure that the timestamps on events reflect distributed ordering. Suppose that node source wants to send a message to node dest, and node source has current clock value T_source. The events that precede that message on node source have smaller timestamps. In addition, consider an event at node dest that follows the receipt of that message. That event must have a timestamp greater than T_source by Lamport's advancing rule above. Hence all the events on node source that preceded the sending of the message have lower timestamps than the events on node dest following the receipt of the message. This is Lamport's distributed "happens-before" relation, and the Lamport clock capture that relation.
Hydroflow Time
As a built-in primitive, Hydroflow defines time only for a single transducer, as a sequence of consecutive ticks without any gaps.
Thus the main difference between Hydroflow events and Lamport events are:
- Batched Events: Hydroflow treats the ingestion of a batch of multiple inbound events as a single tick. TODO: is it possible to limit batch size to 1?
- Fixpoints between Events: Hydroflow requires a fixpoint computation to complete between ticks.
- Consecutive Ticks: the built-in clock primitive in Hydroflow always advances sequentially and cannot skip a tick like the Lamport clock does.
Implementing Distributed Time in Hydroflow
Although Lamport clocks are not built into Hydroflow, it is straightforward to implement them in Hydroflow. Alternatively, one can implement more sophisticated distributed clocks like vector clocks in Hydroflow instead. By leaving this decision to the user, Hydroflow can be used in a variety of distributed time models.
TODO: add example of implementing Lamport clocks?.
Debugging
Error Handling
Architecture
Hydroflow graphs are divided into two layers: the outer scheduled layer and inner compiled layer.
In the mermaid diagrams generated for Hydroflow, the scheduler is responsible for the outermost gray boxes (the subgraphs) and handoffs, while the insides of the gray boxes are compiled via the compiled layer. As a reminder, here is the graph from the reachability chapter, which we will use a running example:
%%{init: {'theme': 'base', 'themeVariables': {'clusterBkg':'#ddd'}}}%%
flowchart TD
classDef pullClass fill:#02f,color:#fff,stroke:#000
classDef pushClass fill:#ff0,stroke:#000
linkStyle default stroke:#aaa,stroke-width:4px,color:red,font-size:1.5em;
subgraph "sg_1v1 stratum 0"
1v1[\"(1v1) <tt>source_iter(vec! [0])</tt>"/]:::pullClass
2v1[\"(2v1) <tt>source_stream(edges_recv)</tt>"/]:::pullClass
3v1[\"(3v1) <tt>merge()</tt>"/]:::pullClass
7v1[\"(7v1) <tt>map(| v | (v, ()))</tt>"/]:::pullClass
4v1[\"(4v1) <tt>join()</tt>"/]:::pullClass
5v1[/"(5v1) <tt>flat_map(| (src, ((), dst)) | [src, dst])</tt>"\]:::pushClass
6v1[/"(6v1) <tt>tee()</tt>"\]:::pushClass
10v1["(10v1) <tt>handoff</tt>"]:::otherClass
10v1--1--->3v1
1v1--0--->3v1
2v1--1--->4v1
3v1--->7v1
7v1--0--->4v1
4v1--->5v1
5v1--->6v1
6v1--0--->10v1
end
subgraph "sg_2v1 stratum 1"
8v1[/"(8v1) <tt>unique()</tt>"\]:::pushClass
9v1[/"(9v1) <tt>for_each(| x | println! ("Reached: {}", x))</tt>"\]:::pushClass
8v1--->9v1
end
6v1--1--->11v1
11v1["(11v1) <tt>handoff</tt>"]:::otherClass
11v1===o8v1
The Hydroflow Architecture Design Doc contains a more detailed explanation of this section. Note that some aspects of the design doc are not implemented (e.g. early yielding) or may become out of date as time passes.
Scheduled Layer
The scheduled layer is dynamic: it stores a list of operators (or "subgraphs") as well as buffers ("handoffs") between them. The scheduled layer chooses how to schedule the operators (naturally), and when each operator runs it pulls from its input handoffs and pushes to its output handoffs. This setup is extremely flexible: operators can have any number of input or output handoffs so we can easily represent any graph topology. However this flexibility comes at a performance cost due to the overhead of scheduling, buffering, and lack of inter-operator compiler optimization.
The compiled layer helps avoids the costs of the scheduled layer. We can combine several operators into a subgraph which are compiled and optimized as a single scheduled subgraph. The scheduled layer then runs the entire subgraph as if it was one operator with many inputs and outputs. Note the layering here: the compiled layer does not replace the scheduled layer but instead exists within it.
Compiled Layer
Rust already has a built-in API similar to dataflow: Iterators.
When they work well, they work really well and tend to be as fast as for loops.
However, they are limited in the flow graphs they can represent. Each operator
in a Iterator takes ownership of, and pulls from, the previous operator.
Taking two iterators as inputs and merging them together (e.g. with
.chain(...)
or .zip(...))
is natural and performant as we can pull from both. However if we want an
iterator to split into multiple outputs then things become tricky. Itertools::tee()
does just this by cloning each incoming item into two output buffers, but this
requires allocation and could cause unbounded buffer growth if the outputs are
not read from at relatively even rates.
However, if instead iterators were push-based, where each operator owns one or more output operators, then teeing is very easy, just clone each element and push to (i.e. run) both outputs. So that's what we did, created push-based iterators to allow fast teeing or splitting in the compiled layer.
Pull-based iterators can be connected to push-based iterators at a single "pivot" point. Together, this pull-to-push setup dictates the shape compiled subgraphs can take. Informally, this is like the roots and leaves of a tree. Water flows from the roots (the pull inputs), eventually all join together in the trunk (the pull-to-push pivot), the split up into multiple outputs in the leaves. We refer to this structure as an in-out tree.
| The Oaklandish Logo. |
In the reachability example above, the pivot is the flat_map() operator: it pulls from the join that feeds it, and pushes to the tee that follows it. In essence that flat_map() serves as the main thread of the compiled component.
See Subgraph In-Out Trees for more, including how to convert a graph into in-out trees.
Surface Syntax and APIs
Hydroflow's Surface Syntax hides
the distinction between these two layers. It offers a natural Iterator-like chaining syntax for building
graphs that get parsed and compiled into a scheduled graph of one or more compiled subgraphs. Please see the Surface Syntax docs for more information.
Alternatively, the Core API allows you to interact with handoffs directly at a low
level. It doesn't provide any notion of chainable operators. You can use Rust Iterators
or any other arbitrary Rust code to implement the operators.
The Core API lives in hydroflow::scheduled,
mainly in methods on the Hydroflow struct. Compiled push-based iterators live in hydroflow::compiled. We intend users to use the Surface Syntax as it is much more friendly, but as
Hydroflow is in active development some operators might not be available in
the Surface Syntax, in which case the Core API can be used instead. If you find
yourself in this sitation be sure to submit an issue!
Scheduling
TODO
Handoffs
TODO
Networking
TODO
Subgraph In-Out Trees
Formally, we define an in-out-tree is the union of an in-tree (anti-arborescence) with an out-tree (arborescence) where both trees share the same root node.
 |
| An in-out tree graph. Data flows from the green pull operators on the left, through the yellow pivot, and to the red push operators on the right. |
In this graph representation, each node corresponds to an operator, and the edges direct the flow of data between operators.
Converting Graph
Any graph can be partitioned into in-out trees. Any non-trivial graph will have many possible partitionings to choose from; a useful heuristic is to partition the graph into as few subgraphs as possible, in order to minimize scheduling overheads.
Most graphs are pretty simple and can be partitioned with a bit of eye-balling. To do this systematically, we can use a simple coloring algorithm.
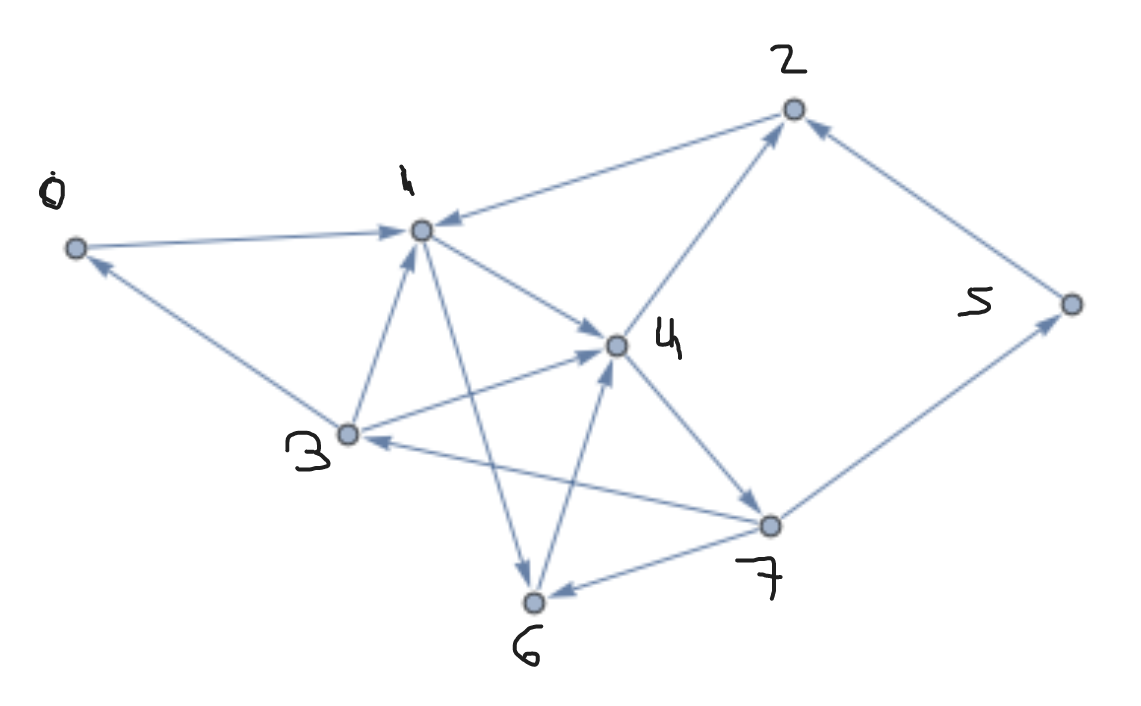 |
| An example directed graph. |
To identify the in-out trees in an arbitrary directed graph, first identify any nodes which have multiple inputs and outputs and mark these as pull-to-push pivots (yellow in the example). Mark any nodes with multiple inputs (and a single output) as pull (green) and any nodes with multiple outputs as push (red).
In the example:
| Pivots (yellow) | Pulls (green) | Pushes (red) |
|---|---|---|
| 1, 4 | 2 | 3, 7 |
Finally any one-in-one-out nodes should be marked the same as their neighbors (either green pull or red push). If we have green pull -> red push that becomes a yellow pivot. And if red push -> green pull that becomes a blue handoff node, and this is a division between subgraphs. Note that a subgraph can have a handoff with itself; this forms a loop.
 |
| The graph above converted and partitioned into two in-out trees. One is outlined in yellow and the other in red. For the corresponding Hydroflow graph, green nodes are pull, red nodes are push, yellow are pivots, and blue are handoffs. |
In the example partitioning above, some nodes have been split into multiple and labelled with suffixes to make the pivots and handoffs more explicit.
The lattices Crate
The lattices crate provides ergonomic and compsable lattice types. Users can also implement
their own lattices via a few simple traits.
Lattices are an incredibly powerful mathematical concept which can greatly simplify the trickiness of distributed computing. They align very well with the reality of what happens physically in a distrubted system; even when data messages are reordered or duplicated, if that data is represented as lattices all machines will always reach the same end result simply by merging the data together. One popular way of lattices are currently used in distributed systems is as the data underlying Conflict-free Replicated Data Types (CRDTs).
Lattices also allow us to harness the power of the CALM Theorem: "a program has a consistent, coordination-free distributed implementation if and only if it is monotonic." Lattice state is always monotonic, meaning any part of a distributed system built on lattice state can be freely distributed with no coordination overhead. The goal of the Hydro Project is to allow users to write programs that automatically scale and distribute effortlessly.
For more information on the underlying mathematics of lattices and monotonicity, take a look at Lattice Math section of the Hydroflow Book and Section 2 of the Hydroflow Thesis.
Take a look at the lattice rustdocs.
Lattices
lattices provides implementations of common lattice types:
Min<T>andMax<T>- totally-orderd lattices.set_union::SetUnion- set-union lattice of scalar values.map_union::MapUnion- scalar keys with nested lattice values.Bottom<Lat>- wraps a lattice inOptionwithNoneas the new bottom value.Pair<LatA, LatB>- product of two nested lattices.DomPair<LatKey, LatVal>* - a versioned pair where theLatKeydominates theLatVal.Fake<T>* - a single constant value which cannot be merged.
*Special implementations which do not obey all lattice properties but are still useful under certain circumstances.
Additionally, custom lattices can be made by implementing the traits below.
Traits
A type becomes a lattice by implementing one or more traits starting with Merge. These traits
are already implemented for all the provided lattice types.
Merge
The main trait is Merge, which defines a lattice merge function (AKA "join" or "least upper
bound"). Implementors must define the Merge::merge method which does a merge in-place into
&mut self. The method must return true if self was modified (i.e. the value got larger in the
lattice partial order) and false otherwise (i.e. other was smaller than self). The Merge::merge_owned
function, which merges two owned values, is provided.
The merge method must be associative, commutative, and idempotent. This is not checked by the
compiler, but the implementor can use the test::check_lattice_properties method to spot-check
these properties on a collection of values.
PartialOrd, LatticeOrd, and NaiveLatticeOrd
Rust already has a trait for partial orders, PartialOrd, which should be implemented on lattice
types. However that trait is not specific to lattice partial orders, therefore we provide theLatticeOrd<Rhs>: PartialOrd<Rhs>
marker trait to denote when a PartialOrd implementation is a lattice partial order. LatticeOrd
must always agree with the Merge function.
Additionally, the sealed NaiveLatticeOrd trait is provided on all lattice types that implement
Merge and Clone. This trait provides a naive_cmp method which derives a lattice order from
the Merge function directly. However the implementation is generally slow and inefficient.
Implementors should use the test::check_partial_ord_properties method to check their
PartialOrd implementation, and should use the test::check_lattice_ord to ensure the partial
order agrees with the Merge-derived NaiveLatticeOrd order.
ConvertFrom
ConvertFrom is equivalent to the std::convert::From trait but with some extra
lattice-specific semantics. ConvertFrom should be implemented only between different
representations of the same lattice type, e.g. between set_union::SetUnionBTreeSet and set_union::SetUnionHashSet.
For compound lattice (lattices with nested lattice types), the ConvertFrom implementation should
be recursive for those nested lattices.
Next
Take a look at Lattice Math for a simple explanation and summary of what
lattices are exactly.
See the lattice rustdocs here.
Lattice Math
Lattices are a simple but powerful mathematic concept that can greatly simplify programming distributed systems.
Lattices For Dummies
So, what is a lattice? Lattices are conceptually very simple, so lets explain them without too much mathy language. A lattice is some type of thing that has a very special merge function. The merge function combines two things and produces an output things. The core feature of lattices is that the merge function has some special properties: associativity, commutativity, and idempotence (ACI).
Lets start with a simple example of something which turns out to not be a lattice; numbers and addition. Numbers are a type of thing, and addition is a function that takes two input numbers and produces and output numbers! But does it satisfy the ACI properties?
Let's start with commutativity. A function is commutativity if it doesn't matter if you swap its two inputs: Addition is commutative, so that property is satisfied! (In contrast, subtraction is not commutative).
Next associativity. A function is associative if, when there are multiple calls together, it does not matter in what order you evaluate the calls: Addition satisfies associativity! (Again, subtraction is not associative -- if you subtract a subtraction then you're doing addition!)
Finally, idempotence. A function is idempotent if when you give it the same value twice it returns that same value. Addition is NOT idempotent, because is , not just . This works for , but not for all numbers.
Now lets look at something that is a lattice. Numbers and the max function. It is
commutiative; the max of is the same as the max of . It is associative; the max of
will always be the same no mater what order you look at them in. And, unlike addition,
it is idempotent; the max of and is always just .
The most standard, canonical example of a lattice is sets with the union function. It is commutative and associative; it doesn't matter what order you union sets together, the result will always be the same. And it is idempotent; a set unioned with itself is the same set.
Lattice Partial Order
Lattices are tied to and often defined in terms of some sort of "partial order". What is a partial order? It's like a normal order, where you can say " comes before ", but it is partial because sometimes say " and are incomparable" instead.
The merge function actually creates a partial order on the elements of the lattice. If you merge and together, but the output is still just unchanged, than we can say that is smaller than . If you merge and and get out, then is larger. Finally, if you merge and and get a new value out, then and are incomparable.
For the number-max lattice, the partial order created by the max merge function is actually just
numerical order. Additionally, it is a total order, meaning all pairs of items are comparable.
 |
A visualization of the max total order over positive integers. |
For the set-union lattice the partial order matches subset order. before is the same as is a subset of (). If two sets have mismatched elements than they are incomparable.
 |
| A visualization of the set-union partial order over three elements, . By KSmrq |
{kind=link}
In the example diagram, is less (smaller) than , so there is a path from the former to the later. In contrast, there is no path between and for example, so they are incomparable.
The merge function is also called the least upper bound (LUB). This name comes from the partial order interpretation. When merging two elements, the result is the smallest (least) item that is still greater than both elements. Hence least upper bound.
Lattice Definitions, At A Glance
A join-semilattice with domain with and join (or "merge") function has the following properties:
The join function creates a partial order : Read as " preceedes ", or " dominates ".
The smallest element in a lattice domain , if it exists, is the bottom, : The largest element in a lattice domain , if it exists, is the top, :
Separately, meet-semilattices and join-semilattices are equivalent structures.
The CALM Theorem and Monotonicity
The CALM Theorem (Consistency As Logical Monotonicity) tells us: "a program has a consistent, coordination-free distributed implementation if and only if it is monotonic"
A function is monotonic if it preserves a partial ordering of its domain to a (possibly different) partial ordering of its codomain.
Lattice Morphism
A function from lattice domain to lattice codomain is a morphism if it structurally preserves merges, i.e. merges distribute across the function. For all : (Because both the domain and codomain are semilattice spaces, semilattice homomorphism is the most precise term for this.)
Lattice morphisms are a special kind of monotonic function which are differentially computable. Because merge distributes over a morphism, we can evaluate the morphisms on a small "delta" of data and merge that delta into the existing result rather than recompute the entire morphism on all data.
Further Reading
TODO
Concepts
- p1 (Mingwei) Hydroflow and Rust: how do they go together?
- State, control, scoping
- p1 State over time
- lifetimes
- explicit deletion
- p3 Coordination tricks?
- End-of-stream to Distributed EOS?
Docs
- p1
hydroflowstruct and its methods - p2 Review the ops docs
Operators not discussed
- dest_sink
- identity
- repeat_iter
- unzip
- p1 *fold* -- add to chapter on [state](state.md)
- p1 *reduce* -- add to chapter on [state](state.md)
- p1 *group_by* -- add to chapter on [state](state.md)
- p3 *sort_by* -- add to chapter on [state](state.md)
- p2 *next_stratum* -- add to chapter on [time](time.md)
- p2 *next_tick* -- add to chapter on [time](time.md)
- p2 *inspect* -- add to chapter on [debugging](debugging.md)
- p2 *null* -- add to chapter on [debugging](debugging.md)
How-Tos and Examples
- p1 Lamport clocks
- p2 Vector clocks
- p2 A partitioned Service
- p2 A replicated Service
- p2 Interfacing with external data
- p2 Interfacing with external services
- p1 Illustrate
'staticand'ticklifetimes (KVS) - p3 Illustrate the
next_stratumoperator for atomicity (eg Bloom's upsert<+-operator) - p3 Illustrate ordered streams (need
zipoperator ... what's the example?) - p3 Actor model implementation (Borrow an Akka or Ray Actors example?)
- p3 Futures emulation? (Borrow a Ray example)
- p2 Illustrate external storage source and sink (e.g. for WAL of KVS)
Odds and ends taken out of other chapters
-
Document the methods on the
hydroflowstruct -- especially the run methods.- The
run_tick(),run_stratum(),run(), andrun_async()methods provide other ways to control the graph execution. - Also
run_available()next_stratum()andrecv_eventsare important
- The
-
Make sure
src/examples/echoserveris the same as the template project -- or better, find a way to do that via github actions or a github submodule
What's covered in examples
-
Concepts covered
- cargo generate for templating
- Hydroflow program specs embedded in Rust
- Tokio Channels and how to use them in Hydroflow
- Network sources and sinks (source_stream)
- Built-in serde (source_stream_serde, dest_sink_serde)
- Hydroflow syntax: operators, ->, variables, indexing multi-input/output operators
- running Hydroflow via
run_availableandrun_async - Recursion via cyclic dataflow
- Fixpoints and Strata
- Template structure: clap, message types
- source_stdin
- Messages and
demux - broadcast pattern
- gated buffer pattern
- bootstrapping pipelines
-
Operators covered
- cross_join
- demux
- dest_sink_serde
- difference
- filter
- filter_map
- flatten
- flat_map
- for_each
- join
- map
- merge
- source_iter
- source_stdin
- source_stream
- source_stream_serde
- tee
- unique
FAQ
Q: How is Hydroflow different from dataflow systems like Spark, Flink, or MapReduce?
A: Hydroflow is designed as a substrate for building a wide range of distributed systems; traditional software dataflow systems like the ones mentioned are targeted more narrowly at large-scale data processing. As such, Hydroflow differs from these systems in several ways:
First, Hydroflow is a lower-level abstraction than the systems mentioned. Hydroflow adopts a dataflow abstraction for specifying a transducer running on a single core; one implementes a distributed system out of multiple Hydroflow transducers. By contrast, Spark, Flink and MapReduce are distributed systems, which make specific choices for implementing issues like scheduling, fault tolerance, and so on.
Second, the systems mentioned above were designed specifically for distributed data processing tasks. By contrast, Hydroflow is designed as a compiler target for many possible language models. Distributed dataflow systems like those mentioned above are one possible higher-level model one could build with Hydroflow, but there are many others.
Third, Hydroflow is a reactive dataflow engine, optimized for low-latency handling of asynchronous events and messages in a long-lived service. For example, one can build low-level protocol handlers in Hydroflow for implementing distributed protocols like Paxos or Two-Phase Commit with low latency.
Q: What model of parallelism does Hydroflow use? SPMD? MPMD? Actors? MPI?
A: As a substrate for building individual nodes in a distributed systems, Hydroflow does not make any assumptions about the model of parallelism used. One can construct a distributed system out of Hydroflow transducers that use any model of parallelism, including SPMD, MPMD, Actors or MPI Collective Operations. Hydroflow provides abstractions for implementing individual transducers to handle inputs, computing, and emitting outputs in a general-purpose manner.
That said, it is common practice to deploy many instance of the same Hydroflow transducer; most distributed systems built in Hydroflow therefore have some form of SPMD parallelism. (This is true of most distributed systems in general.)